目录
[TOC]
一. Hadoop篇
1. 并行计算模型MapReduce
1.1 MapReduce 的工作原理
MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。(这句话记住了是可以用来装逼的)

执行步骤:切片>分词>映射>分区>排序>聚合>shuffle>reduce
1)Map()阶段
读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数
重写map(),对第一步产生的<k,v>进行处理,转换为新的<k,v>输出
对输出的key、value进行分区
对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中
2)Reduce阶段
- 多个map任务的输出,按照不同的分区,通过网络复制到不同的reduce节点上
- 对多个map的输出进行合并、排序。
- 重写reduce函数实现自己的逻辑,对输入的key、value处理,转换成新的key、value输出
- 把reduce的输出保存到文件中
特别说明:
切片 不属于map阶段,但却是map阶段的输入,是集群对输入数据的解析处理
分词,映射,分区,排序,聚合 都属map阶段
混洗 横跨map阶段和reduce阶段,其发生在map阶段的输出和reduce的输入阶段
规约 属reduce阶段 规约结果是reduce阶段的输出,输出格式由集群默认或用户自定义
分词即map()函数的输入与map阶段的输入略有差别,他的输入是切片结果的kv形式,行号(偏移量)与行内容
补充
切片:HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
Map任务的数量:Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
Reduce任务的数量: 最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目 通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
1.2 MapReduce中shuffle工作流程及优化
shuffle主要功能是把map task的输出结果有效地传送到reduce端。
简单些可以这样说,每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
前奏:
1. 在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。
2. 在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“aaa”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。前面我们知道这个job有3个reduce task,到底当前的“aaa”应该交由哪个reduce去做呢,是需要现在决定的。
主要工作流程map端分区,排序,溢写,拷贝,reduce端合并
1)Map端shuffle


分区Partition
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
写入内存缓冲区: 在我们的例子中,“aaa”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。 这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。
溢写Spill: 这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
排序Sort: 当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
合并Map端:在这里我们可以想想,因为map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并,那么这种合并应该是体现是磁盘文件中的。从官方图上也可以看到写到磁盘中的溢写文件是对不同的reduce端的数值做过合并。所以溢写过程一个很重要的细节在于,如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录。
CombineReduce端:在针对每个reduce端而合并数据时,有些数据可能像这样:“aaa”/1, “aaa”/1。对于WordCount例子,就是简单地统计单词出现的次数,如果在同一个map task的结果中有很多个像“aaa”一样出现多次的key,我们就应该把它们的值合并到一块,这个过程叫reduce也叫combine。但MapReduce的术语中,reduce只指reduce端执行从多个map task取数据做计算的过程。除reduce外,非正式地合并数据只能算做combine了。其实大家知道的,MapReduce中将Combiner等同于Reducer。
2)Reduce端shuffle
1. Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2. Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。
增加combiner,压缩溢写的文件。
3. Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,之后的性能优化篇我再说。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。


3)shuffle优化
压缩:对数据进行压缩,减少写读数据量;
减少不必要的排序:并不是所有类型的Reduce需要的数据都是需要排序的,排序这个nb的过程如果不需要最好还是不要的好;
内存化:Shuffle的数据不放在磁盘而是尽量放在内存中,除非逼不得已往磁盘上放;当然了如果有性能和内存相当的第三方存储系统,那放在第三方存储系统上也是很好的;这个是个大招;
补充
1. Map端
1) io.sort.mb
用于map输出排序的内存缓冲区大小
类型:Int
默认:100mb
备注:如果能估算map输出大小,就可以合理设置该值来尽可能减少溢出写的次数,这对调优很有帮助。
2) io.sort.spill.percent
map输出排序时的spill阀值(即使用比例达到该值时,将缓冲区中的内容spill 到磁盘)
类型:float
默认:0.80
3) io.sort.factor
归并因子(归并时的最多合并的流数),map、reduce阶段都要用到
类型:Int
默认:10
备注:将此值增加到100是很常见的。
4) min.num.spills.for.combine
运行combiner所需的最少溢出写文件数(如果已指定combiner)
类型:Int
默认:3
5) mapred.compress.map.output
map输出是否压缩
类型:Boolean
默认:false
备注:如果map输出的数据量非常大,那么在写入磁盘时压缩数据往往是个很好的主意,因为这样会让写磁盘的速度更快,节约磁盘空间,并且减少传给reducer的数据量。
6) mapred.map.output.compression.codec
用于map输出的压缩编解码器
类型:Classname
默认:org.apache.hadoop.io.compress.DefaultCodec
备注:推荐使用LZO压缩。Intel内部测试表明,相比未压缩,使用LZO压缩的 TeraSort作业,运行时间减少60%,且明显快于Zlib压缩。
7) tasktracker.http.threads
每个tasktracker的工作线程数,用于将map输出到reducer。
(注:这是集群范围的设置,不能由单个作业设置)
类型:Int
默认:40
备注:tasktracker开http服务的线程数。用于reduce拉取map输出数据,大集群可以将其设为40~50。
2. reduce端
1) mapred.reduce.slowstart.completed.maps
调用reduce之前,map必须完成的最少比例
类型:float
默认:0.05
2) mapred.reduce.parallel.copies
reducer在copy阶段同时从mapper上拉取的文件数
类型:int
默认:5
3) mapred.job.shuffle.input.buffer.percent
在shuffle的复制阶段,分配给map输出的缓冲区占堆空间的百分比
类型:float
默认:0.70
4) mapred.job.shuffle.merge.percent
map输出缓冲区(由mapred.job.shuffle.input.buffer.percent定义)使用比例阀值,当达到此阀值,缓冲区中的数据将会被归并然后spill 到磁盘。
类型:float
默认:0.66
5) mapred.inmem.merge.threshold
map输出缓冲区中文件数
类型:int
默认:1000
备注:0或小于0的数意味着没有阀值限制,溢出写将有mapred.job.shuffle.merge.percent单独控制。
6) mapred.job.reduce.input.buffer.percent
在reduce过程中,在内存中保存map输出的空间占整个堆空间的比例。
类型:float
默认:0.0
备注:reduce阶段开始时,内存中的map输出大小不能大于该值。默认情况下,在reduce任务开始之前,所有的map输出都合并到磁盘上,以便为reducer提供尽可能多的内存。然而,如果reducer需要的内存较少,则可以增加此值来最小化访问磁盘的次数,以提高reduce性能。
2. 分布式文件系统HDFS
2.1 HDFS 的体系架构和读写流程
1)体系架构
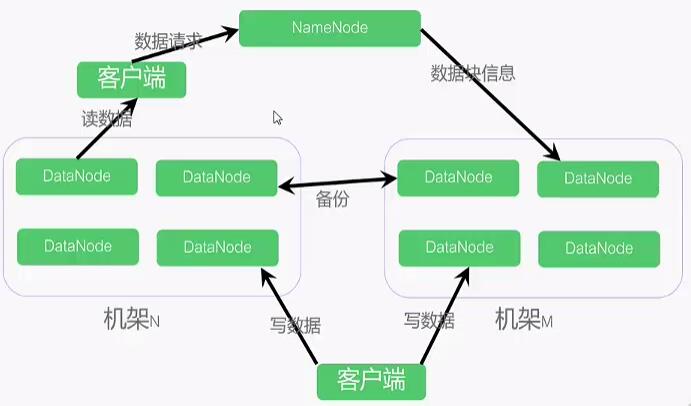
采用Master-Slaver模式:
NameNode中心服务器(Master):维护文件系统树、以及整棵树内的文件目录、负责整个数据集群的管理。
DataNode分布在不同的机架上(Slaver):在客户端或者NameNode的调度下,存储并检索数据块,并且定期向NameNode发送所存储的数据块的列表。
客户端与NameNode获取元数据;与DataNode交互获取数据。
默认情况下,每个DataNode都保存了3个副本,其中两个保存在同一个机架的两个不同的节点上。另一个副本放在不同机架上的节点上。
补充
基本概念
机架:HDFS集群,由分布在多个机架上的大量DataNode组成,不同机架之间节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。
数据块(block):HDFS最基本的存储单元,默认为64M,用户可以自行设置大小。
元数据:指HDFS文件系统中,文件和目录的属性信息。HDFS实现时,采用了 镜像文件(Fsimage) + 日志文件(EditLog)的备份机制。文件的镜像文件中内容包括:修改时间、访问时间、数据块大小、组成文件的数据块的存储位置信息。目录的镜像文件内容包括:修改时间、访问控制权限等信息。日志文件记录的是:HDFS的更新操作。
NameNode启动的时候,会将镜像文件和日志文件的内容在内存中合并。把内存中的元数据更新到最新状态。
用户数据:HDFS存储的大部分都是用户数据,以数据块的形式存放在DataNode上。
在HDFS中,NameNode 和 DataNode之间使用TCP协议进行通信。DataNode每3s向NameNode发送一个心跳。每10次心跳后,向NameNode发送一个数据块报告自己的信息,通过这些信息,NameNode能够重建元数据,并确保每个数据块有足够的副本。
2)HDFS文件读流程

(1)客户端通过调用FileSystem的open方法获取需要读取的数据文件,对HDFS来说该FileSystem就是DistributeFileSystem
(2)DistributeFileSystem通过RPC来调用NameNode,获取到要读的数据文件对应的bock存储在哪些NataNode之上
(3)客户端先到最佳位置(距离最近)的DataNode上调用FSDataInputStream的read方法,通过反复调用read方法,可以将数据从DataNode传递到客户端
(4)当读取完所有的数据之后,FSDataInputStream会关闭与DataNode的连接,然后寻找下一块的最佳位置,客户端只需要读取连续的流。
(5)一旦客户端完成读取操作之后,就对FSDataInputStream调用close方法来完成资源的关闭操作
3)HDFS文件写操作

(1)客户端通过调用DistributeFileSystem的create方法来创建一个文件
(2)DistributeFileSystem会对NameNode发起RPC请求,在文件系统的名称空间中创建一个新的文件,此时会进行各种检查,比如:检查要创建的文件是否已经存在,如果该文件不存在,NameNode就会为该文件创建一条元数据记录
(3)客户端调用FSDataOututStream的write方法将数据写到一个内部队列中。假设副本数为3,那么将队列中的数据写到3个副本对应的存储的DataNode上。
(4)FSDataOututStream内部维护着一个确认队列,当接收到所有DataNode确认写完的消息后,数据才会从确认队列中删除
(5)当客户端完成数据的写入后,会对数据流调用close方法来关闭相关资源
补充
写入过程客户端奔溃怎么处理?(租约恢复)
2.2 HDFS 常用操作命令
1)查看文件常用命令
- 命令格式
1.hdfs dfs -ls path 查看文件列表
2.hdfs dfs -lsr path 递归查看文件列表
3.hdfs dfs -du path 查看path下的磁盘情况,单位字节 - 使用示例
1.hdfs dfs -ls / 查看当前目录
2.hdfs dfs - lsr / 递归查看当前目录
2)创建文件夹
- 命令格式
hdfs dfs -mkdir path - 使用用例
hdfs dfs -mkdir /user/iron
注:该命令可递归创建文件夹,不可重复创建,在Linux文件系统中不可见
3)创建文件
- 命令格式
hdfs dfs -touchz path - 使用用例
hdfs dfs -touchz /user/iron/iron.txt
注:该命令不可递归创建文件即当该文件的上级目录不存在时无法创建该文件,可重复创建但会覆盖原有的内容
4)复制文件和目录
- 命令格式
hdfs dfs -cp 源目录 目标目录 - 使用用例
hdfs dfs -cp /user/iron /user/iron01
注:该命令会将源目录的整个目录结构都复制到目标目录中
hdfs dfs -cp /user/iron/* /user/iron01
注:该命令只会将源目录中的文件及其文件夹都复制到目标目录中
5)移动文件和目录
- 命令格式
hdfs dfs -mv 源目录 目标目录 - 使用用例
hdfs dfs -mv /user/iron /user/iron01
6)赋予权限
- 命令格式
hdfs dfs -chmod [权限参数][拥有者][:[组]] path - 使用用例
hdfs dfs -chmod 777 /user/*
注:该命令是将user目录下的所用文件及其文件夹(不包含子文件夹中的文件)赋予最高权限:读,写,执行
777表示该用户,该用户的同组用户,其他用户都具有最高权限
7)上传文件
- 命令格式
hdfs dfs -put 源文件夹 目标文件夹 - 使用用例
hdfs dfs -put /home/hadoop01/iron /user/iron01
注:该命令上传Linux文件系统中iron整个文件夹
hdfs dfs -put /home/hadoop01/iron/* /user/iron01
注:该命令上传Linux文件系统中iron文件夹中的所有文件(不包括文件夹)
类似命令:
hdfs dfs -copyFromLocal 源文件夹 目标文件夹 作用同put
hdfs dfs -moveFromLocal 源文件夹 目标文件夹 上传后删除本地
8)下载文件
- 命令格式
hdfs dfs -get源文件夹 目标文件夹 - 使用用例
hdfs dfs -get /user/iron01 /home/hadoop01/iron
注:该命令下载hdfs文件系统中的iron01整个文件夹到Linux文件系统中
hdfs dfs -get /user/iron01/* /home/hadoop01/iron
注:该命令下载hdfs文件系统中的iron01整个文件夹到Linux文件系统中(不包含文件夹)
类似命令
hdfs dfs -copyToLocal 源文件夹 目标文件夹 作用同get
hdfs dfs -moveToLocal 源文件夹 目标文件夹 get后删除源文件
9)查看文件内容
- 命令格式
hadoop fs -cat path 从头查看这个文件
hadoop fs -tail path 从尾部查看最后1K - 使用用例
hadoop fs -cat /userjzl/home/book/1.txt
hadoop fs -tail /userjzl/home/book/1.txt
10)删除文件
- 命令格式
hdfs dfs -rm 目标文件
hdfs dfs -rmr 目标文件 递归删除(慎用) - 使用用例
hdfs dfs -rm /user/test.txt 删除test.txt文件
hdfs dfs -rmr /user/testdir 递归删除testdir文件夹
注:rm不可以删除文件夹
3. 通用资源管理器Yarn
3.1 Yarn 的产生背景和架构
3.2 Yarn 中的角色划分和各自的作用
3.3 Yarn 的配置和常用的资源调度策略
3.4 Yarn 进行一次任务资源调度的过程
4. 数据仓库工具Hive
4.1 Hive 和普通关系型数据库的区别
- Hive和关系型数据库存储文件的系统不同, Hive使用的是HDFS(Hadoop的分布式文件系统),关系型数据则是服务器本地的文件系统。
- Hive使用的计算模型是MapReduce,而关系型数据库则是自己设计的计算模型.
- 关系型数据库都是为实时查询业务设计的,而Hive则是为海量数据做挖掘而设计的,实时性差;实时性的区别导致Hive的应用场景和关系型数据库有很大区别。
- Hive很容易扩展自己的存储能力和计算能力,这几是继承Hadoop的,而关系型数据库在这方面要比Hive差很多。
4.2 Hive内部表和外部表的区别
- 创建表时:创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。
- 删除表时:在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
4.3 Hive分区表和分桶表的区别
分区在HDFS上的表现形式是一个目录, 分桶是一个单独的文件
分区: 细化数据管理,直接读对应目录,缩小mapreduce程序要扫描的数据量
分桶: 1、提高join查询的效率(用分桶字段做连接字段)2、提高采样的效率
4.4 Hive 支持哪些数据格式
可支持Text,SequenceFile,ParquetFile,ORC,RCFILE等
补充
TextFile: TextFile文件不支持块压缩,默认格式,数据不做压缩,磁盘开销大,数据解析开销大。这边不做深入介绍。
RCFile: Record Columnar的缩写。是Hadoop中第一个列文件格式。能够很好的压缩和快速的查询性能,但是不支持模式演进。通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量。 RCFile是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
ORCFile: 存储方式:数据按行分块 每块按照列存储 ,压缩快 快速列存取,效率比rcfile高,是rcfile的改良版本,相比RC能够更好的压缩,能够更快的查询,但还是不支持模式演进。
Parquet: Parquet能够很好的压缩,有很好的查询性能,支持有限的模式演进。但是写速度通常比较慢。这中文件格式主要是用在Cloudera Impala上面的。
性能对比
- 读操作

存储效率

4.5 Hive元数据库作用及存储内容
本质上只是用来存储hive中有哪些数据库,哪些表,表的模式,目录,分区,索引以及命名空间。为数据库创建的目录一般在hive数据仓库目录下
4.6 HiveSQL 支持的几种排序区别
1)Order By:全局排序,只有一个Reducer
使用 ORDER BY 子句排序
ASC(ascend): 升序(默认)
DESC(descend): 降序
ORDER BY 子句在SELECT语句的结尾
案例实操
查询员工信息按工资升序排列
hive (default)> select * from emp order by sal;查询员工信息按工资降序排列
hive (default)> select * from emp order by sal desc;
2)Sort By:每个MapReduce内部排序
Sort By:对于大规模的数据集order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by。Sort by为每个reducer产生一个排序文件。每个Reducer内部进行排序,对全局结果集来说不是排序。
- 设置reduce个数
hive (default)> set mapreduce.job.reduces=3;- 查看设置reduce个数
hive (default)> set mapreduce.job.reduces;- 根据部门编号降序查看员工信息
hive (default)> select * from emp sort by deptno desc;- 将查询结果导入到文件中(按照部门编号降序排序)
hive (default)> insert overwrite local directory '/opt/module/datas/sortby-result'
select * from emp sort by deptno desc;3)Distribute By:分区排序
Distribute By: 在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。distribute by 子句可以做这件事。distribute by类似MR中partition(自定义分区),进行分区,结合sort by使用。 对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。
案例实操:
- 先按照部门编号分区,再按照员工编号降序排序。
hive (default)> set mapreduce.job.reduces=3;
hive (default)> insert overwrite local directory '/opt/module/datas/distribute-result' select * from emp distribute by deptno sort by empno desc;注意:
distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。
Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。
4)Cluster By
当distribute by和sorts by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。
- 以下两种写法等价
hive (default)> select * from emp cluster by deptno;
hive (default)> select * from emp distribute by deptno sort by deptno;
--注意:按照部门编号分区,不一定就是固定死的数值,可以是20号和30号部门分到一个分区里面去。
--cluster by :sort by 和 distribute by的组合4.7 Hive 的动态分区
往hive分区表中插入数据时,如果需要创建的分区很多,比如以表中某个字段进行分区存储,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以hive提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
使用动态分区表必须配置的参数
set hive.exec.dynamic.partition =true(默认false),表示开启动态分区功能;set hive.exec.dynamic.partition.mode = nonstrict(默认strict),表示允许所有分区都是动态的,否则必须有静态分区字段;
动态分区相关调优参数
set hive.exec.max.dynamic.partitions.pernode=100(默认100,一般可以设置大一点,比如1000); 表示每个maper或reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。set hive.exec.max.dynamic.partitions =1000(默认值) ; 表示一个动态分区语句可以创建的最大动态分区个数,超出报错;set hive.exec.max.created.files =10000(默认) 全局可以创建的最大文件个数,超出报错。
4.8 Hive MapJoin
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率
使用
方法一:
在Hive0.11前,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小
SELECT /*+ MAPJOIN(smalltable)*/ .key,value
FROM smalltable JOIN bigtable ON smalltable.key = bigtable.key方法二:
在Hive0.11后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机
hive.auto.convert.join默认值为true,自动开启MAPJOIN优化
hive.mapjoin.smalltable.filesize默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中
注意:使用默认启动该优化的方式如果出现默名奇妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化
hive.auto.convert.join=false(关闭自动MAPJOIN转换操作)
hive.ignore.mapjoin.hint=false(不忽略MAPJOIN标记)对于以下查询是不支持使用方法二(MAPJOIN标记)来启动该优化的
select /*+MAPJOIN(smallTableTwo)*/ idOne, idTwo, value FROM
( select /*+MAPJOIN(smallTableOne)*/ idOne, idTwo, value FROM
bigTable JOIN smallTableOne on (bigTable.idOne = smallTableOne.idOne)
) firstjoin
JOIN
smallTableTwo ON (firstjoin.idTwo = smallTableTwo.idTwo) 但是,如果使用的是方法一即没有MAPJOIN标记则以上查询语句将会被作为两个MJ执行,进一步的,如果预先知道表大小是能够被加载进内存的,则可以通过以下属性来将两个MJ合并成一个MJ
hive.auto.convert.join.noconditionaltask:Hive在基于输入文件大小的前提下将普通JOIN转换成MapJoin,并是否将多个MJ合并成一个
hive.auto.convert.join.noconditionaltask.size:多个MJ合并成一个MJ时,其表的总的大小须小于该值,同时hive.auto.convert.join.noconditionaltask必须为true4.9 HQL 和 SQL 有哪些常见的区别
总体一致:Hive-sql与SQL基本上一样,因为当初的设计目的,就是让会SQL不会编程MapReduce的也能使用Hadoop进行处理数据。
区别:Hive没有delete和update。
Hive不支持等值连接
--SQL中对两表内联可以写成: select * from dual a,dual b where a.key = b.key; --Hive中应为 select * from dual a join dual b on a.key = b.key; --而不是传统的格式: SELECT t1.a1 as c1, t2.b1 as c2FROM t1, t2 WHERE t1.a2 = t2.b2分号字符
--分号是SQL语句结束标记,在HiveQL中也是,但是在HiveQL中,对分号的识别没有那么智慧,例如: select concat(key,concat(';',key)) from dual; --但HiveQL在解析语句时提示: FAILED: Parse Error: line 0:-1 mismatched input '<EOF>' expecting ) in function specification --解决的办法是,使用分号的八进制的ASCII码进行转义,那么上述语句应写成: select concat(key,concat('\073',key)) from dual;IS [NOT] NULL
--SQL中null代表空值, 值得警惕的是, --在HiveQL中String类型的字段若是空(empty)字符串, 即长度为0, 那么对它进行IS NULL的判断结果是False.Hive不支持将数据插入现有的表或分区中
hive不支持INSERT INTO 表 Values(), UPDATE, DELETE操作
hive支持嵌入mapreduce程序,来处理复杂的逻辑
如:FROM ( 1. MAP doctext USING 'python wc_mapper.py' AS (word, cnt) 2. FROM docs 3. CLUSTER BY word 4. ) a 5. REDUCE word, cnt USING 'python wc_reduce.py'; --doctext: 是输入 --word, cnt: 是map程序的输出 --CLUSTER BY: 将wordhash后,又作为reduce程序的输入并且map程序、reduce程序可以单独使用,如: 1. FROM ( 2. FROM session_table 3. SELECT sessionid, tstamp, data 4. DISTRIBUTE BY sessionid SORT BY tstamp 5. ) a 6. REDUCE sessionid, tstamp, data USING 'session_reducer.sh'; --DISTRIBUTE BY: 用于给reduce程序分配行数据
4.10 Hive开窗函数
假设有如下表格(loan)。表中包含贷款人的唯一标识,贷款日期,以及贷款金额。
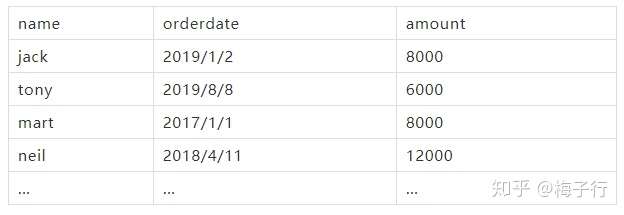
1. SUM(), MIN(),MAX(),AVG()等聚合函数,可以直接使用 over() 进行分区计算。
SELECT *,
/*前三次贷款的金额之和*/
SUM(amount) OVER (PARTITION BY name ORDER BY orderdate ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv1,
/*历史所有贷款 累加到下一次贷款 的金额之和*/
SUM(amount) OVER (PARTITION BY name ORDER BY orderdate ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING) AS pv2
FROM loan ; 其中,窗口函数over()使得聚合函数sum()可以在限定的窗口中进行聚合。本例子中,第一条语句计算每个人当前记录的前三条贷款金额之和。第二条语句计算截至到下一次贷款,客户贷款的总额。
窗口的限定语法为:ROWS BETWEEN 一个时间点 AND 一个时间点。时间节点可以使用:
- n PRECEDING : 前n行 n preceding
- n FOLLOWING:后n行
- CURRENT ROW : 当前行
如果不想限制具体的行数,可以将 n 替换为 UNBOUNDED.比如从起始到当前,可以写为:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
窗口函数over()和group by 的最大区别,在于group by之后其余列也必须按照此分区进行计算,而over()函数使得单个特征可以进行分区。
2. NTILE(), ROW_NUMBER(), RANK(), DENSE_RANK(),可以为数据集新增加序列号。
SELECT *,
#将数据按name切分成10区,并返回属于第几个分区
NTILE(10) OVER (PARTITION BY name ORDER BY orderdate) AS f1,
#将数据按照name分区,并按照orderdate排序,返回排序序号
ROW_NUMBER() OVER (PARTITION BY name ORDER BY orderdate) AS f2,
#将数据按照name分区,并按照orderdate排序,返回排序序号
RANK() OVER (PARTITION BY name ORDER BY orderdate) AS f3,
#将数据按照name分区,并按照orderdate排序,返回排序序号
DENSE_RANK() OVER (PARTITION BY name ORDER BY orderdate) AS f4
FROM loan;其中第一个函数NTILE(10)是将数据按name切分成10区,并返回属于第几个分区。
可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
语法是:
ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num然后可以根据桶号,选取前或后 n分之几的数据。
后面的三个函数的功能看起来很相似。区别在于当数据中出现相同值得时候,如何编号。
- ROW_NUMBER()返回的是一列连续的序号。

- RANK()对于数值相同的这一项会标记为相同的序号,而下一个序号跳过。比如{4,5,6}变成了{4,4,6}.

- DENSE_RANK()对于数值相同的这一项,也会标记为相同的序号,但下一个序号并不会跳过。比如{4,5,6}变成了{4,4,5}.

3. LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()函数返回一系列指定的点
SELECT *,
#取上一笔贷款的日期,缺失默认填NULL
LAG(orderdate, 1) OVER(PARTITION BY name ORDER BY orderdate) AS last_dt,
#取下一笔贷款的日期,缺失指定填'1970-1-1'
LEAD(orderdate, 1,'1970-1-1') OVER(PARTITION BY name ORDER BY orderdate) AS next_dt,
#取最早一笔贷款的日期
FIRST_VALUE(orderdate) OVER(PARTITION BY name ORDER BY orderdate) AS first_dt,
#取新一笔贷款的日期
LAST_VALUE(orderdate) OVER(PARTITION BY name ORDER BY orderdate) AS latest_dt
FROM loan;LAG(n)将数据向前错位 n 行。LEAD(n)将数据向后错位 n 行。FIRST_VALUE()取当前分区中的第一个值。 LAST_VALUE()取当前分区最后一个值。注意:这四个函数取出的都是某个字段,不是整条记录
4. GROUPING SET(),with CUBE, with ROLLUP 对 group by 进行限制
SELECT
A,B,C
FROM loan
#分别按照月份和日进行分区
GROUP BY substring(orderdate,1,7),orderdate
GROUPING SETS(substring(orderdate,1,7), orderdate)
ORDER BY GROUPING__ID; GROUPING__ID是GROUPING_SET()的操作之后自动生成的。生成GROUPING__ID是为了区分每条输出结果是属于哪一个group by的数据。它是根据group by后面声明的顺序字段,是否存在于当前group by中的一个二进制位组合数据。GROUPING SETS()必须先做GROUP BY操作。
比如(A,C)的group_id: group_id(A,C) = grouping(A)+grouping(B)+grouping (C) 的结果就是:二进制:101 也就是5.
如果解释器发现group by A,C 但是select A,B,C 那么运行时会将所有from 表取出的结果复制一份,B都置为null,也就是在结果中,B都为null.
SELECT
A,B,C
FROM loan
#分别按照月份和日进行分区
GROUP BY substring(orderdate,1,7),orderdate
with CUBE
ORDER BY GROUPING__ID; with CUBE 和GROUPING_SET()的区别就是,with CUBE 返回的是group by 字段的笛卡尔积。
SELECT
A,B,C
FROM loan
#分别按照月份和日进行分区
GROUP BY substring(orderdate,1,7),orderdate
with ROLLUP
ORDER BY GROUPING__ID; with ROLLUP则不会产生第二列为键的聚合结果,在本例子中,只按照 substring(orderdate,1,7)进行展示。所以使用with ROLLUP时,要注意group by 后面字段的顺序。
4.11 HiveUDF UDAF UDTF函数
UDF:一进一出
实现方法:
继承UDF类
重写evaluate方法
将该java文件编译成jar
在终端输入如下命令:
hive> add jar test.jar; hive> create temporary function function_name as 'com.hrj.hive.udf.UDFClass'; hive> select function_name(t.col1) from table t; hive> drop temporary function function_name;
UDAF:多进一出
实现方法:
用户的UDAF必须继承了
org.apache.hadoop.hive.ql.exec.UDAF;用户的UDAF必须包含至少一个实现了
org.apache.hadoop.hive.ql.exec的静态类,诸如实现了 UDAFEvaluator一个计算函数必须实现的5个方法的具体含义如下:
- init():主要是负责初始化计算函数并且重设其内部状态,一般就是重设其内部字段。一般在静态类中定义一个内部字段来存放最终的结果。
- iterate():每一次对一个新值进行聚集计算时候都会调用该方法,计算函数会根据聚集计算结果更新内部状态。当输 入值合法或者正确计算了,则就返回true。
- terminatePartial():Hive需要部分聚集结果的时候会调用该方法,必须要返回一个封装了聚集计算当前状态的对象。
- merge():Hive进行合并一个部分聚集和另一个部分聚集的时候会调用该方法。
- terminate():Hive最终聚集结果的时候就会调用该方法。计算函数需要把状态作为一个值返回给用户。
部分聚集结果的数据类型和最终结果的数据类型可以不同。
UDTF:一进多出
实现方法:
继承
org.apache.hadoop.hive.ql.udf.generic.GenericUDTFinitialize():UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)
process:初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward() 调用产生一行;如果产生多列 可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数
最后close()方法调用,对需要清理的方法进行清理
4.12 Hive数据倾斜问题
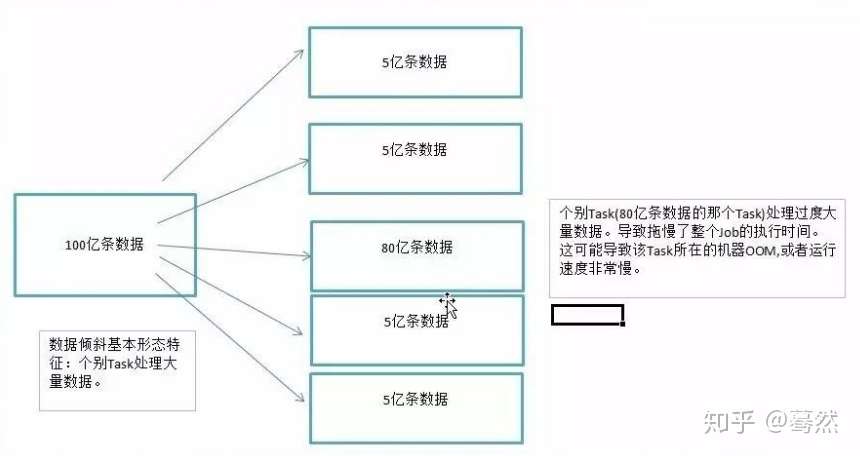
0. 什么是数据倾斜
对于集群系统,一般缓存是分布式的,即不同节点负责一定范围的缓存数据。我们把缓存数据分散度不够,导致大量的缓存数据集中到了一台或者几台服务节点上,称为数据倾斜。一般来说数据倾斜是由于负载均衡实施的效果不好引起的。
来源百度百科
对于数据计算过程来说,数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
1. 数据倾斜的现象
多数task执行速度较快,少数task执行时间非常长,或者等待很长时间后提示你内存不足,执行失败。
2. 数据倾斜的影响
1)数过多的数据在同一个task中执行,将会把executor撑爆,造成OOM,程序终止运行。,据倾斜直接会导致一种情况:Out Of Memory。
2)运行速度慢 ,spark中一个stage的执行时间受限于最后那个执行完的task,因此运行缓慢的任务会拖累整个程序的运行速度(分布式程序运行的速度是由最慢的那个task决定的)。要是发生在Shuffle阶段。同样Key的数据条数太多了。导致了某个key(下图中的80亿条)所在的Task数据量太大了。远远超过其他Task所处理的数据量。
一个经验结论是:一般情况下,OOM的原因都是数据倾斜\
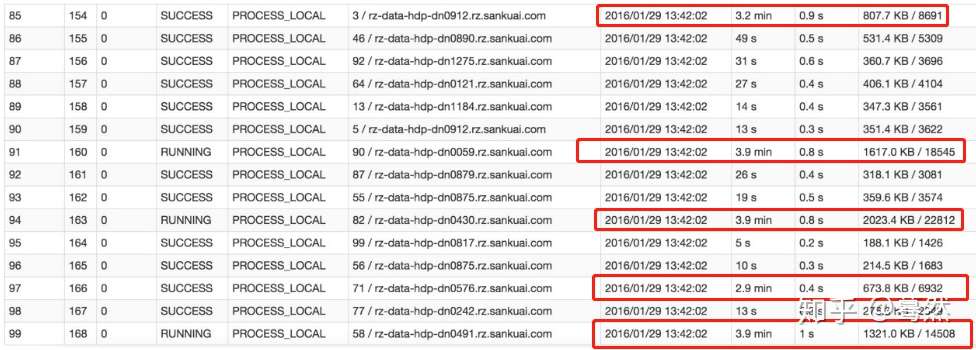
3. 如何定位数据倾斜
数据倾斜一般会发生在shuffle过程中。很大程度上是你使用了可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
原因: 查看任务-》查看Stage-》查看代码
某个task执行特别慢的情况
某个task莫名其妙内存溢出的情况
查看导致数据倾斜的key的数据分布情况
也可从以下几种情况考虑:
1、是不是有OOM情况出现,一般是少数内存溢出的问题
2、是不是应用运行时间差异很大,总体时间很长
3、需要了解你所处理的数据Key的分布情况,如果有些Key有大量的条数,那么就要小心数据倾斜的问题
4、一般需要通过Spark Web UI和其他一些监控方式出现的异常来综合判断
5、看看代码里面是否有一些导致Shuffle的算子出现
4. 数据倾斜的几种典型情况(重点)
- 数据源中的数据分布不均匀,Spark需要频繁交互
- 数据集中的不同Key由于分区方式,导致数据倾斜
- JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
- 聚合操作中,数据集中的数据分布不均匀(主要)
- JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
- JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
- 数据集中少数几个key数据量很大,不重要,其他数据均匀
注意:
需要处理的数据倾斜问题就是Shuffle后数据的分布是否均匀问题
只要保证最后的结果是正确的,可以采用任何方式来处理数据倾斜,只要保证在处理过程中不发生数据倾斜就可以
5. 数据倾斜的处理方法
发现数据倾斜的时候,不要急于提高executor的资源,修改参数或是修改程序,首先要检查数据本身,是否存在异常数据。
5.1 检查数据,找出异常的key
如果任务长时间卡在最后1个(几个)任务,首先要对key进行抽样分析,判断是哪些key造成的。
选取key,对数据进行抽样,统计出现的次数,根据出现次数大小排序取出前几个
df.select("key").sample(false,0.1).(k=>(k,1)).reduceBykey(_+_).map(k=>(k._2,k._1)).sortByKey(false).take(10) 如果发现多数数据分布都较为平均,而个别数据比其他数据大上若干个数量级,则说明发生了数据倾斜。
经过分析,倾斜的数据主要有以下三种情况:
null(空值)或是一些无意义的信息()之类的,大多是这个原因引起。
无效数据,大量重复的测试数据或是对结果影响不大的有效数据。
有效数据,业务导致的正常数据分布。
解决办法
第1,2种情况,直接对数据进行过滤即可。
第3种情况则需要进行一些特殊操作,常见的有以下几种做法。
隔离执行,将异常的key过滤出来单独处理,最后与正常数据的处理结果进行union操作。
对key先添加随机值,进行操作后,去掉随机值,再进行一次操作。
使用reduceByKey 代替 groupByKey
使用map join。
举例:
如果使用reduceByKey因为数据倾斜造成运行失败的问题。具体操作如下:将原始的 key 转化为 key + 随机值(例如Random.nextInt)
对数据进行 reduceByKey(func)
将 key + 随机值 转成 key
再对数据进行 reduceByKey(func)
tip1: 如果此时依旧存在问题,建议筛选出倾斜的数据单独处理。最后将这份数据与正常的数据进行union即可。tips2: 单独处理异常数据时,可以配合使用Map Join解决
5.1.1 数据源中的数据分布不均匀,Spark需要频繁交互
解决方案1:避免数据源的数据倾斜
实现原理:通过在Hive中对倾斜的数据进行预处理,以及在进行kafka数据分发时尽量进行平均分配。这种方案从根源上解决了数据倾斜,彻底避免了在Spark中执行shuffle类算子,那么肯定就不会有数据倾斜的问题了。
方案优点:实现起来简单便捷,效果还非常好,完全规避掉了数据倾斜,Spark作业的性能会大幅度提升。
方案缺点:治标不治本,Hive或者Kafka中还是会发生数据倾斜。
适用情况:在一些Java系统与Spark结合使用的项目中,会出现Java代码频繁调用Spark作业的场景,而且对Spark作业的执行性能要求很高,就比较适合使用这种方案。将数据倾斜提前到上游的Hive ETL,每天仅执行一次,只有那一次是比较慢的,而之后每次Java调用Spark作业时,执行速度都会很快,能够提供更好的用户体验。
总结:前台的Java系统和Spark有很频繁的交互,这个时候如果Spark能够在最短的时间内处理数据,往往会给前端有非常好的体验。这个时候可以将数据倾斜的问题抛给数据源端,在数据源端进行数据倾斜的处理。但是这种方案没有真正的处理数据倾斜问题
5.1.2 数据集中的不同Key由于分区方式,导致数据倾斜
解决方案1:调整并行度
实现原理:增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。
方案优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
方案缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
实践经验:该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,都无法处理。
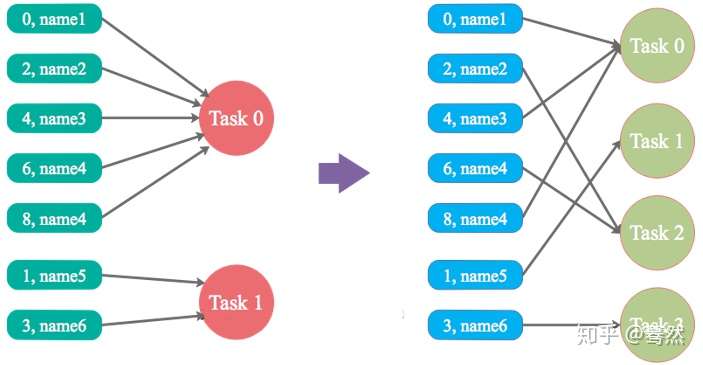
总结:调整并行度:适合于有大量key由于分区算法或者分区数的问题,将key进行了不均匀分区,可以通过调大或者调小分区数来试试是否有效
解决方案2:
缓解数据倾斜**(自定义Partitioner)**
适用场景:大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案: 使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
优势: 不影响原有的并行度设计。如果改变并行度,后续Stage的并行度也会默认改变,可能会影响后续Stage。
劣势: 适用场景有限,只能将不同Key分散开,对于同一Key对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的Partitioner,不够灵活。
5.2 检查Spark运行过程相关操作
5.2.1 JOIN操作中,一个数据集中的数据分布不均匀,另一个数据集较小(主要)
解决方案:Reduce side Join转变为Map side Join
方案适用场景:在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(比如几百M),比较适用此方案。
方案实现原理:普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
方案优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
方案缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。
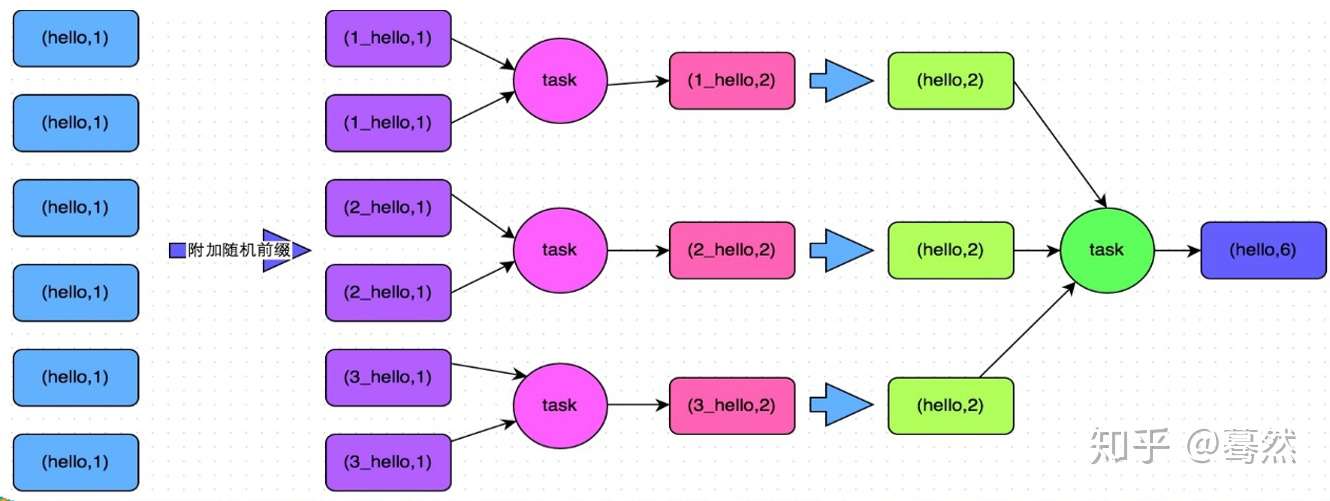
5.2.2 聚合操作中,数据集中的数据分布不均匀(主要)
解决方案:两阶段聚合(局部聚合+全局聚合)
适用场景:对RDD执行reduceByKey等聚合类shuffle算子或者在Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案
实现原理:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
优点:对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
缺点:仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案
将相同key的数据分拆处理
5.2.3 JOIN操作中,两个数据集都比较大,其中只有几个Key的数据分布不均匀
解决方案:为倾斜key增加随机前/后缀
适用场景:两张表都比较大,无法使用Map侧Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案:将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(笛卡尔积,相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join后去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势:相对于Map侧Join,更能适应大数据集的Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势:如果倾斜Key非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜Key与非倾斜Key分开处理,需要扫描数据集两遍,增加了开销。
注意:具有倾斜Key的RDD数据集中,key的数量比较少
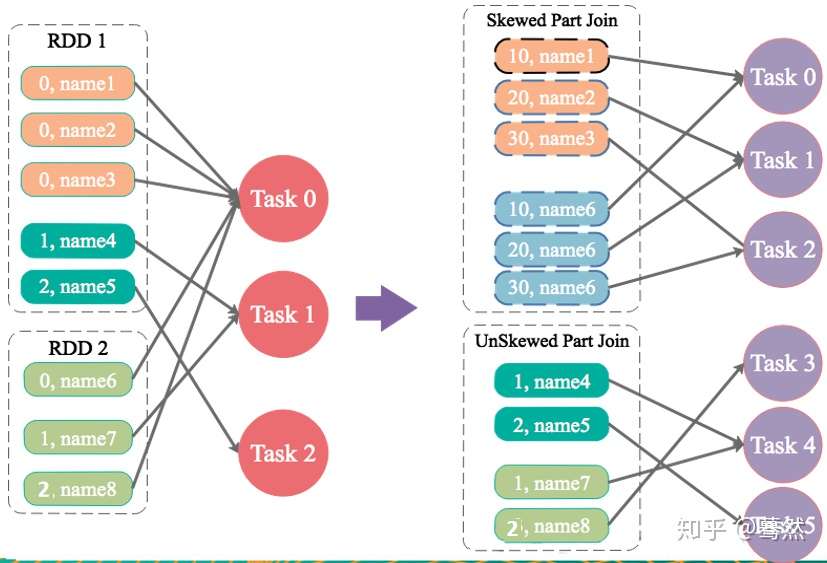
5.2.4 JOIN操作中,两个数据集都比较大,有很多Key的数据分布不均匀
解决方案:随机前缀和扩容RDD进行join
适用场景:如果在进行join操作时,RDD中有大量的key导致数据倾斜,那么进行分拆key也没什么意义。
实现思路:将该RDD的每条数据都打上一个n以内的随机前缀。同时对另外一个正常的RDD进行扩容,将每条数据都扩容成n条数据,扩容出来的每条数据都依次打上一个0~n的前缀。最后将两个处理后的RDD进行join即可。和上一种方案是尽量只对少数倾斜key对应的数据进行特殊处理,由于处理过程需要扩容RDD,因此上一种方案扩容RDD后对内存的占用并不大;而这一种方案是针对有大量倾斜key的情况,没法将部分key拆分出来进行单独处理,因此只能对整个RDD进行数据扩容,对内存资源要求很高。
优点:对join类型的数据倾斜基本都可以处理,而且效果也相对比较显著,性能提升效果非常不错。
缺点:该方案更多的是缓解数据倾斜,而不是彻底避免数据倾斜。而且需要对整个RDD进行扩容,对内存资源要求很高。
实践经验:曾经开发一个数据需求的时候,发现一个join导致了数据倾斜。优化之前,作业的执行时间大约是60分钟左右;使用该方案优化之后,执行时间缩短到10分钟左右,性能提升了6倍。
注意:将倾斜Key添加1-N的随机前缀,并将被Join的数据集相应的扩大N倍(需要将1-N数字添加到每一条数据上作为前缀)
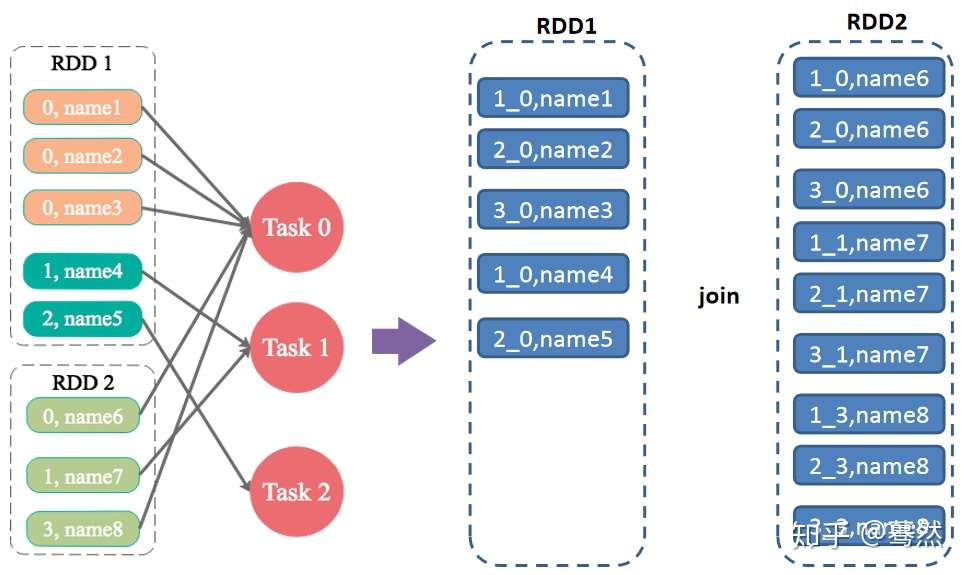
5.2.5 数据集中少数几个key数据量很大,不重要,其他数据均匀
解决方案:过滤少数倾斜Key
适用场景:如果发现导致倾斜的key就少数几个,而且对计算本身的影响并不大的话,那么很适合使用这种方案。比如99%的key就对应10条数据,但是只有一个key对应了100万数据,从而导致了数据倾斜。
优点:实现简单,而且效果也很好,可以完全规避掉数据倾斜。
缺点:适用场景不多,大多数情况下,导致倾斜的key还是很多的,并不是只有少数几个。
实践经验:在项目中我们也采用过这种方案解决数据倾斜。有一次发现某一天Spark作业在运行的时候突然OOM了,追查之后发现,是Hive表中的某一个key在那天数据异常,导致数据量暴增。因此就采取每次执行前先进行采样,计算出样本中数据量最大的几个key之后,直接在程序中将那些key给过滤掉。
4.13 HiveSQL 的优化(系统参数调整、SQL 语句优化)
Hive优化目标
- 在有限的资源下,执行效率更高
常见问题
- 数据倾斜
- map数设置
- reduce数设置
- 其他
Hive执行
HQL –> Job –> Map/Reduce
执行计划
- explain [extended] hql
- 样例
- select col,count(1) from test2 group by col;
- explain select col,count(1) from test2 group by col;
Hive表优化
分区
- set hive.exec.dynamic.partition=true;
- set hive.exec.dynamic.partition.mode=nonstrict;
- 静态分区
- 动态分区
分桶
- set hive.enforce.bucketing=true;
- set hive.enforce.sorting=true;
数据
- 相同数据尽量聚集在一起
Hive Job优化
并行化执行
- 每个查询被hive转化成多个阶段,有些阶段关联性不大,则可以并行化执行,减少执行时间
- set hive.exec.parallel= true;
- set hive.exec.parallel.thread.numbe=8;
本地化执行
- job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB)
- job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4)
- job的reduce数必须为0或者1
- set hive.exec.mode.local.auto=true;
- 当一个job满足如下条件才能真正使用本地模式:
job合并输入小文件
- set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
- 合并文件数由mapred.max.split.size限制的大小决定
job合并输出小文件**
- set hive.merge.smallfiles.avgsize=256000000;当输出文件平均小于该值,启动新job合并文件
- set hive.merge.size.per.task=64000000;合并之后的文件大小
JVM重利用
- set mapred.job.reuse.jvm.num.tasks=20;
- JVM重利用可以使得JOB长时间保留slot,直到作业结束,这在对于有较多任务和较多小文件的任务是非常有意义的,减少执行时间。当然这个值不能设置过大,因为有些作业会有reduce任务,如果reduce任务没有完成,则map任务占用的slot不能释放,其他的作业可能就需要等待。
压缩数据
- set hive.exec.compress.output=true;
- set mapred.output.compreession.codec=org.apache.hadoop.io.compress.GzipCodec;
- set mapred.output.compression.type=BLOCK;
- set hive.exec.compress.intermediate=true;
- set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
- set hive.intermediate.compression.type=BLOCK;
- 中间压缩就是处理hive查询的多个job之间的数据,对于中间压缩,最好选择一个节省cpu耗时的压缩方式
- hive查询最终的输出也可以压缩
Hive Map优化
set mapred.map.tasks =10; 无效
(1)默认map个数
- default_num=total_size/block_size;
(2)期望大小
- goal_num=mapred.map.tasks;
(3)设置处理的文件大小
- split_size=max(mapred.min.split.size,block_size);
- split_num=total_size/split_size;
(4)计算的map个数
- compute_map_num=min(split_num,max(default_num,goal_num))
经过以上的分析,在设置map个数的时候,可以简答的总结为以下几点:
- 增大mapred.min.split.size的值
- 如果想增加map个数,则设置mapred.map.tasks为一个较大的值
- 如果想减小map个数,则设置mapred.min.split.size为一个较大的值
- 情况1:输入文件size巨大,但不是小文件
- 情况2:输入文件数量巨大,且都是小文件,就是单个文件的size小于blockSize。这种情况通过增大mapred.min.split.size不可行,需要使用combineFileInputFormat将多个input path合并成一个InputSplit送给mapper处理,从而减少mapper的数量。
map端聚合
- set hive.map.aggr=true;
推测执行
- mapred.map.tasks.apeculative.execution
Hive Shuffle优化
Map端
- io.sort.mb
- io.sort.spill.percent
- min.num.spill.for.combine
- io.sort.factor
- io.sort.record.percent
Reduce端
- mapred.reduce.parallel.copies
- mapred.reduce.copy.backoff
- io.sort.factor
- mapred.job.shuffle.input.buffer.percent
- mapred.job.shuffle.input.buffer.percent
- mapred.job.shuffle.input.buffer.percent
Hive Reduce优化
需要reduce操作的查询
- group by,join,distribute by,cluster by…
- order by比较特殊,只需要一个reduce
- sum,count,distinct…
- 聚合函数
- 高级查询
推测执行
- mapred.reduce.tasks.speculative.execution
- hive.mapred.reduce.tasks.speculative.execution
Reduce优化
- numRTasks = min[maxReducers,input.size/perReducer]
- maxReducers=hive.exec.reducers.max
- perReducer = hive.exec.reducers.bytes.per.reducer
- hive.exec.reducers.max 默认 :999
- hive.exec.reducers.bytes.per.reducer 默认:1G
- set mapred.reduce.tasks=10;直接设置
- 计算公式
Hive查询操作优化
join优化
- 关联操作中有一张表非常小
- 不等值的链接操作
- set hive.auto.current.join=true;
- hive.mapjoin.smalltable.filesize默认值是25mb
- select
/*+mapjoin(A)*/f.a,f.b from A t join B f on (f.a=t.a) - hive.optimize.skewjoin=true;如果是Join过程出现倾斜,应该设置为true
- set hive.skewjoin.key=100000; 这个是join的键对应的记录条数超过这个值则会进行优化
- mapjoin
- 简单总结下,mapjoin的使用场景:
Bucket join
- 两个表以相同方式划分桶
- 两个表的桶个数是倍数关系
- crete table order(cid int,price float) clustered by(cid) into 32 buckets;
- crete table customer(id int,first string) clustered by(id) into 32 buckets;
- select price from order t join customer s on t.cid=s.id
join 优化前
select m.cid,u.id from order m join customer u on m.cid=u.id where m.dt='2013-12-12';- join优化后
select m.cid,u.id from (select cid from order where dt='2013-12-12')m join customer u on m.cid=u.id;group by 优化
hive.groupby.skewindata=true;如果是group by 过程出现倾斜 应该设置为trueset hive.groupby.mapaggr.checkinterval=100000;--这个是group的键对应的记录条数超过这个值则会进行优化
count distinct 优化
优化前
select count(distinct id) from tablename优化后
select count(1) from (select distinct id from tablename) tmp; select count(1) from (select id from tablename group by id) tmp;优化前
select a,sum(b),count(distinct c),count(distinct d) from test group by a优化后
select a,sum(b) as b,count(c) as c,count(d) as d from(select a,0 as b,c,null as d from test group by a,c union all select a,0 as b,null as c,d from test group by a,d union all select a,b,null as c,null as d from test)tmp1 group by a;
#二. Spark篇
1. SparkCore
1.1 Spark工作原理
1. Spark是什么
Spark是一种通用分布式并行计算框架。和Mapreduce最大不同就是spark是基于内存的迭代式计算。
Spark的Job处理的中间输出结果可以保存在内存中,从而不再需要读写HDFS,除此之外,一个MapReduce 在计算过程中只有map 和reduce 两个阶段,处理之后就结束了,而在Spark的计算模型中,可以分为n阶段,因为它内存迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。
因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。其不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。
2. Spark工作原理框图


第一层级
工作流程
a. 构建Spark Application的运行环境(启动SparkContext)
b. SparkContext在初始化过程中分别创建DAGScheduler作业调度和TaskScheduler任务调度两级调度模块
c. SparkContext向资源管理器(可以是Standalone、Mesos、Yarn)申请运行Executor资源;
d. 由资源管理器分配资源并启动StandaloneExecutorBackend,executor,之后向SparkContext申请Task;
e. DAGScheduler将job 划分为多个stage,并将Stage提交给TaskScheduler;
g. Task在Executor上运行,运行完毕释放所有资源。
第二层级
DAGScheduler作业调度生成过程
DAGScheduler是一个面向stage 的作业调度器。
作业调度模块是基于任务阶段的高层调度模块,它为每个Spark作业计算具有依赖关系的多个调度阶段(通常根据shuffle来划分),然后为每个阶段构建出一组具体的任务(通常会考虑数据的本地性等),然后以TaskSets(任务组)的形式提交给任务调度模块来具体执行。
主要三大功能
接受用户提交的job。将job根据类型划分为不同的stage,记录哪些RDD,stage被物化,并在每一个stage内产生一系列的task,并封装成taskset;
决定每个task的最佳位置,任务在数据所在节点上运行,并结合当前的缓存情况,将taskSet提交给TaskScheduler;
重新提交shuffle输出丢失的stage给taskScheduler;
DAG如何将Job划分为多个stage

划分依据:**宽窄依赖**。何时产生宽依赖就会产生一个新的stage,例如reduceByKey,groupByKey,join的算子,会导致宽依赖的产生;一旦遇到宽依赖就划分,然后先提交没有父阶段的stage们,并在提交过程中,计算该stage的task数目以及类型,并提交具体的task,在这些无父阶段的stage提交完之后,依赖该stage 的stage才会提交。
切割规则:从后往前,遇到宽依赖就切割stage;
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分依据就是宽窄依赖,遇到宽依赖就划分stage,每个stage包含一个或多个task,然后将这些task以taskSet的形式提交给TaskScheduler运行,stage是由一组并行的task组成。
一旦driver程序中出现action,就会生成一个job,比如count等,
向DAGScheduler提交job,如果driver程序后面还有action,那么其他action也会对应生成相应的job,所以,driver端有多少action就会提交多少job,这可能就是为什么spark将driver程序称为application而不是job 的原因。
每一个job可能会包含一个或者多个stage,最后一个stage生成result,在提交job 的过程中,DAGScheduler会首先从后往前划分stage,划分的标准就是宽依赖,一旦遇到宽依赖就划分,然后先提交没有父阶段的stage们,并在提交过程中,计算该stage的task数目以及类型,并提交具体的task,在这些无父阶段的stage提交完之后,依赖该stage 的stage才会提交。
第三层级
谈谈spark中的宽窄依赖
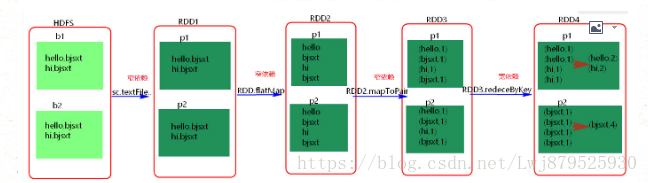
RDD和它的父RDD的关系有两种类型:窄依赖和宽依赖
- 宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition,关系是一对多,父RDD的一个分区的数据去到子RDD的不同分区里面,会有shuffle的产生
- 窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个partition使用,是一对一的,也就是父RDD的一个分区去到了子RDD的一个分区中,这个过程没有shuffle产生
区分的标准就是看父RDD的一个分区的数据的流向,要是流向一个partition的话就是窄依赖,否则就是宽依赖,如图所示:
1.2 Spark的shuffle原理和过程
Shuffle过程框图
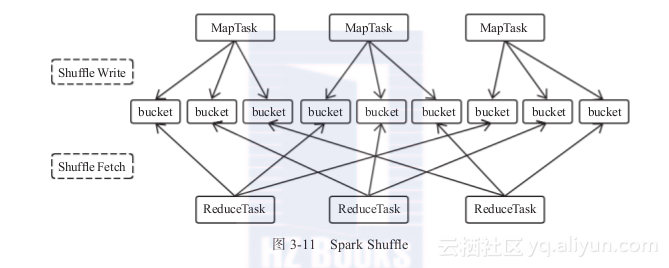
主要逻辑如下:
1)首先每一个MapTask会根据ReduceTask的数量创建出相应的bucket,bucket的数量是M×R,其中M是Map的个数,R是Reduce的个数。
2)其次MapTask产生的结果会根据设置的partition算法填充到每个bucket中。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中。
当ReduceTask启动时,它会根据自己task的id和所依赖的Mapper的id从远端或本地的block manager中取得相应的bucket作为Reducer的输入进行处理。
这里的bucket是一个抽象概念,在实现中每个bucket可以对应一个文件,可以对应文件的一部分或是其他等。
Spark shuffle可以分为两部分:Shuffle Write 和 Shuffle Fetch
Shuffle Write
由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle write 的任务很简单,那么实现也很简单:将 shuffle write 的处理逻辑加入到 ShuffleMapStage(ShuffleMapTask 所在的 stage) 的最后,该 stage 的 final RDD 每输出一个 record 就将其 partition 并持久化。图示如下:
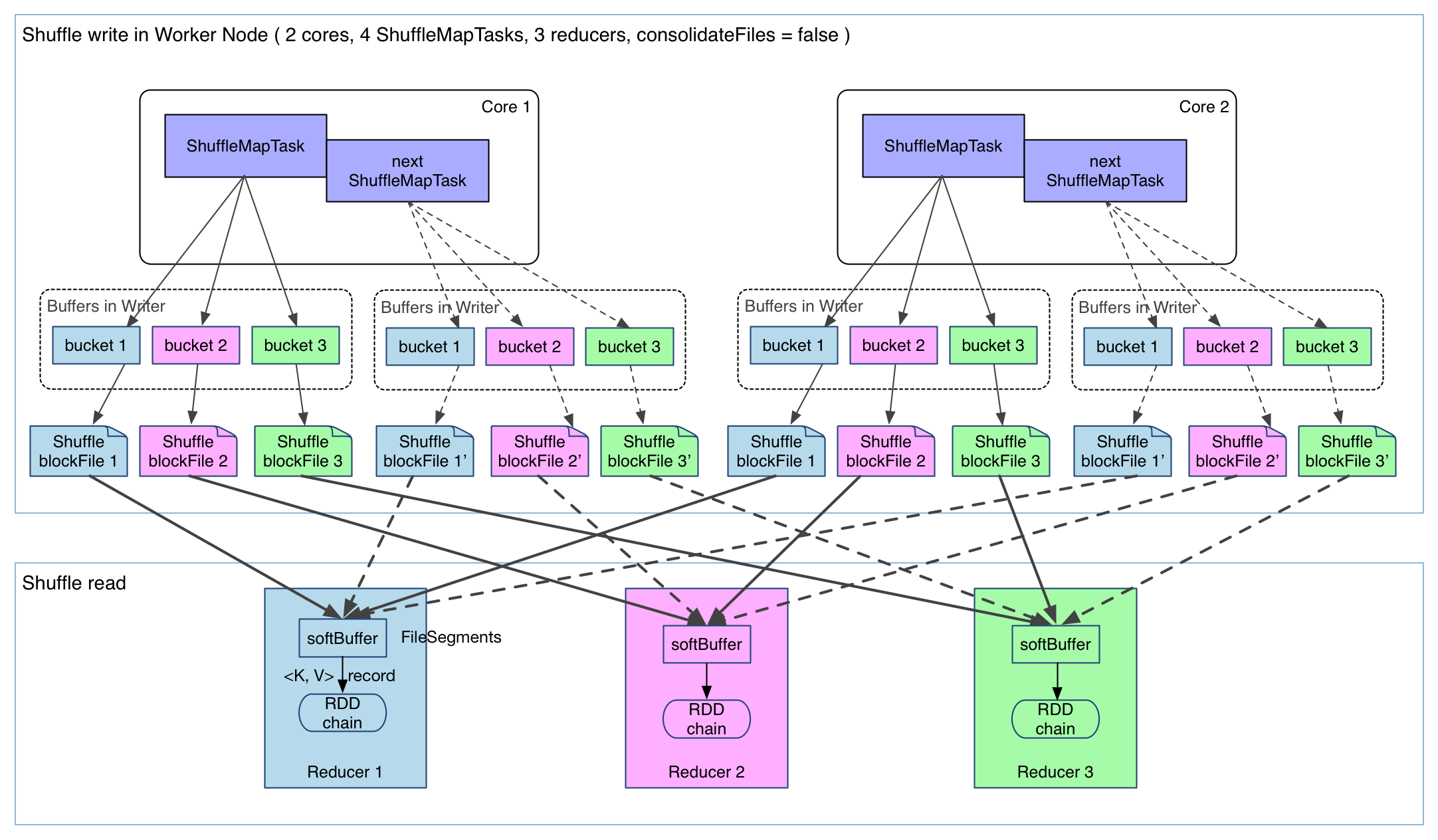
上图有 4 个 ShuffleMapTask 要在同一个 worker node 上运行,CPU core 数为 2,可以同时运行两个 task。每个 task 的执行结果(该 stage 的 finalRDD 中某个 partition 包含的 records)被逐一写到本地磁盘上。每个 task 包含 R 个缓冲区,R = reducer 个数(也就是下一个 stage 中 task 的个数),缓冲区被称为 bucket,其大小为spark.shuffle.file.buffer.kb ,默认是 32KB(Spark 1.1 版本以前是 100KB)。
其实 bucket 是一个广义的概念,代表 ShuffleMapTask 输出结果经过 partition 后要存放的地方,这里为了细化数据存放位置和数据名称,仅仅用 bucket 表示缓冲区。
ShuffleMapTask 的执行过程很简单:先利用 pipeline 计算得到 finalRDD 中对应 partition 的 records。每得到一个 record 就将其送到对应的 bucket 里,具体是哪个 bucket 由partitioner.partition(record.getKey()))决定。每个 bucket 里面的数据会不断被写到本地磁盘上,形成一个 ShuffleBlockFile,或者简称 FileSegment。之后的 reducer 会去 fetch 属于自己的 FileSegment,进入 shuffle read 阶段。
这样的实现很简单,但有几个问题:
- 产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
- 缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 M R 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了
cores * R * 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
目前来看,第二个问题还没有好的方法解决,因为写磁盘终究是要开缓冲区的,缓冲区太小会影响 IO 速度。但第一个问题有一些方法去解决,下面介绍已经在 Spark 里面实现的 FileConsolidation 方法。先上图:
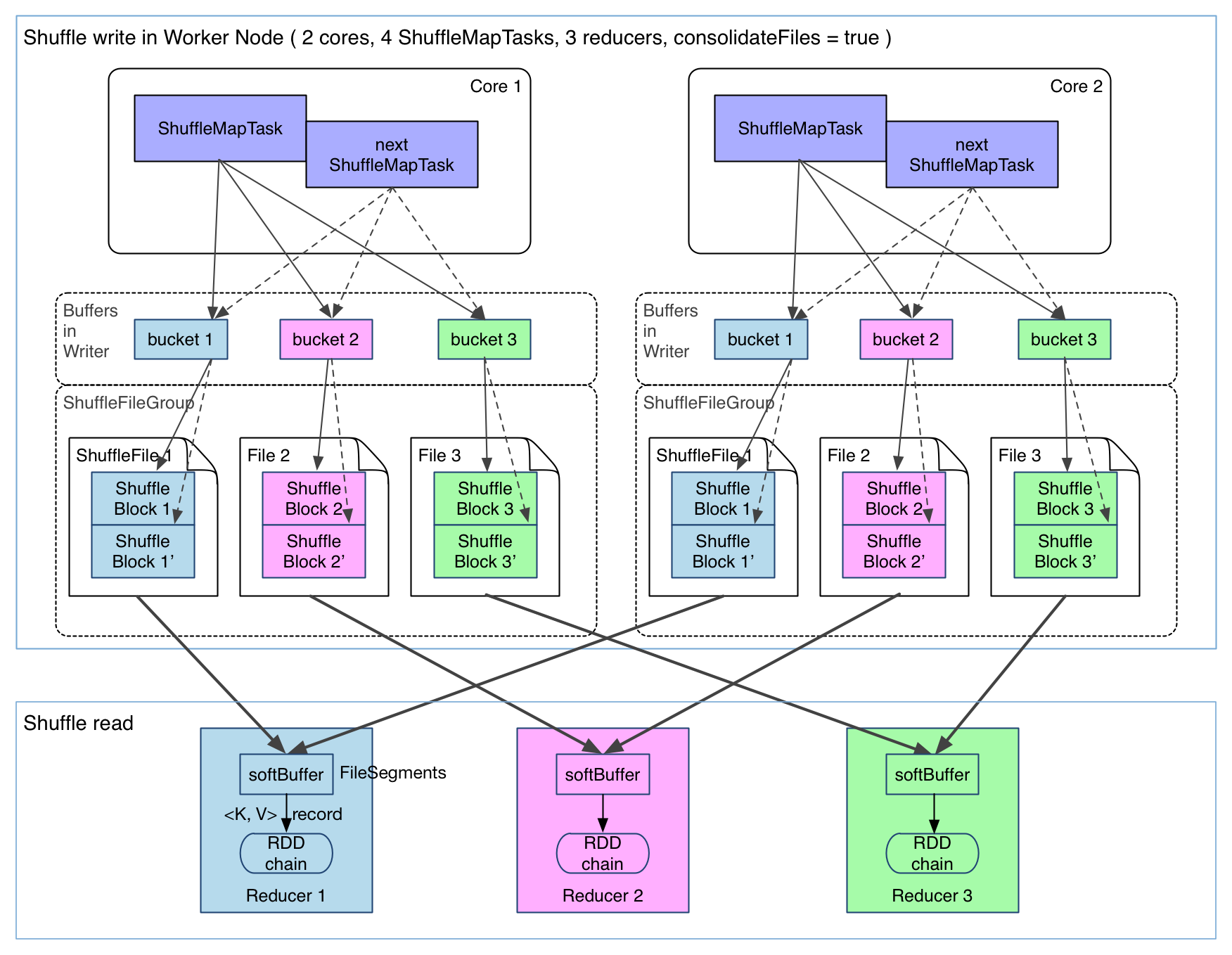
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlocki,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlocki’,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
Shuffle Fetch
先看一张包含 ShuffleDependency 的物理执行图,来自 reduceByKey:
很自然地,要计算 ShuffleRDD 中的数据,必须先把 MapPartitionsRDD 中的数据 fetch 过来。那么问题就来了:
- 在什么时候 fetch,parent stage 中的一个 ShuffleMapTask 执行完还是等全部 ShuffleMapTasks 执行完?
- 边 fetch 边处理还是一次性 fetch 完再处理?
- fetch 来的数据存放到哪里?
- 怎么获得要 fetch 的数据的存放位置?
在什么时候 fetch?当 parent stage 的所有 ShuffleMapTasks 结束后再 fetch。理论上讲,一个 ShuffleMapTask 结束后就可以 fetch,但是为了迎合 stage 的概念(即一个 stage 如果其 parent stages 没有执行完,自己是不能被提交执行的),还是选择全部 ShuffleMapTasks 执行完再去 fetch。因为 fetch 来的 FileSegments 要先在内存做缓冲,所以一次 fetch 的 FileSegments 总大小不能太大。Spark 规定这个缓冲界限不能超过
spark.reducer.maxMbInFlight,这里用 softBuffer 表示,默认大小为 48MB。一个 softBuffer 里面一般包含多个 FileSegment,但如果某个 FileSegment 特别大的话,这一个就可以填满甚至超过 softBuffer 的界限。边 fetch 边处理还是一次性 fetch 完再处理?边 fetch 边处理。本质上,MapReduce shuffle 阶段就是边 fetch 边使用 combine() 进行处理,只是 combine() 处理的是部分数据。MapReduce 为了让进入 reduce() 的 records 有序,必须等到全部数据都 shuffle-sort 后再开始 reduce()。因为 Spark 不要求 shuffle 后的数据全局有序,因此没必要等到全部数据 shuffle 完成后再处理。那么如何实现边 shuffle 边处理,而且流入的 records 是无序的?答案是使用可以 aggregate 的数据结构,比如 HashMap。每 shuffle 得到(从缓冲的 FileSegment 中 deserialize 出来)一个 \ record,直接将其放进 HashMap 里面。如果该 HashMap 已经存在相应的 Key,那么直接进行 aggregate 也就是
func(hashMap.get(Key), Value),比如上面 WordCount 例子中的 func 就是hashMap.get(Key) + Value,并将 func 的结果重新 put(key) 到 HashMap 中去。这个 func 功能上相当于 reduce(),但实际处理数据的方式与 MapReduce reduce() 有差别,差别相当于下面两段程序的差别。// MapReduce reduce(K key, Iterable<V> values) { result = process(key, values) return result } // Spark reduce(K key, Iterable<V> values) { result = null for (V value : values) result = func(result, value) return result }MapReduce 可以在 process 函数里面可以定义任何数据结构,也可以将部分或全部的 values 都 cache 后再进行处理,非常灵活。而 Spark 中的 func 的输入参数是固定的,一个是上一个 record 的处理结果,另一个是当前读入的 record,它们经过 func 处理后的结果被下一个 record 处理时使用。因此一些算法比如求平均数,在 process 里面很好实现,直接
sum(values)/values.length,而在 Spark 中 func 可以实现sum(values),但不好实现/values.length。更多的 func 将会在下面的章节细致分析。fetch 来的数据存放到哪里?刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。这里我们主要讨论处理后的数据,可以灵活设置这些数据是“只用内存”还是“内存+磁盘”。如果
spark.shuffle.spill = false就只用内存。内存使用的是AppendOnlyMap,类似 Java 的HashMap,内存+磁盘使用的是ExternalAppendOnlyMap,如果内存空间不足时,ExternalAppendOnlyMap可以将 \ records 进行 sort 后 spill 到磁盘上,等到需要它们的时候再进行归并,后面会详解。使用“内存+磁盘”的一个主要问题就是如何在两者之间取得平衡?在 Hadoop MapReduce 中,默认将 reducer 的 70% 的内存空间用于存放 shuffle 来的数据,等到这个空间利用率达到 66% 的时候就开始 merge-combine()-spill。在 Spark 中,也适用同样的策略,一旦 ExternalAppendOnlyMap 达到一个阈值就开始 spill,具体细节下面会讨论。怎么获得要 fetch 的数据的存放位置?在上一章讨论物理执行图中的 stage 划分的时候,我们强调 “一个 ShuffleMapStage 形成后,会将该 stage 最后一个 final RDD 注册到
MapOutputTrackerMaster.registerShuffle(shuffleId, rdd.partitions.size),这一步很重要,因为 shuffle 过程需要 MapOutputTrackerMaster 来指示 ShuffleMapTask 输出数据的位置”。因此,reducer 在 shuffle 的时候是要去 driver 里面的 MapOutputTrackerMaster 询问 ShuffleMapTask 输出的数据位置的。每个 ShuffleMapTask 完成时会将 FileSegment 的存储位置信息汇报给 MapOutputTrackerMaster。
1.3 Spark的Stage划分及优化
窄依赖指父RDD的每一个分区最多被一个子RDD的分区所用,表现为
一个父RDD的分区对应于一个子RDD的分区
两个父RDD的分区对应于一个子RDD 的分区。
宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作
Stage:
一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage。Stage的划分,简单的说是以shuffle和result这两种类型来划分。在Spark中有两类task,一类是shuffleMapTask,一类是resultTask,第一类task的输出是shuffle所需数据,第二类task的输出是result,stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作是另一个stage。
比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有shuffle,直接就输出了,那么只有它的task是resultTask,stage也只有一个;
如果是rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage,直接就输出结果了。如果job中有多次shuffle,那么每个shuffle之前都是一个stage.
会根据RDD之间的依赖关系将DAG图划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中
Stage划分思路
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!
而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中。
总结
map,filter为窄依赖,
groupbykey为宽依赖
遇到一个宽依赖就分一个stage
1.4 Spark和MapReduce的区别
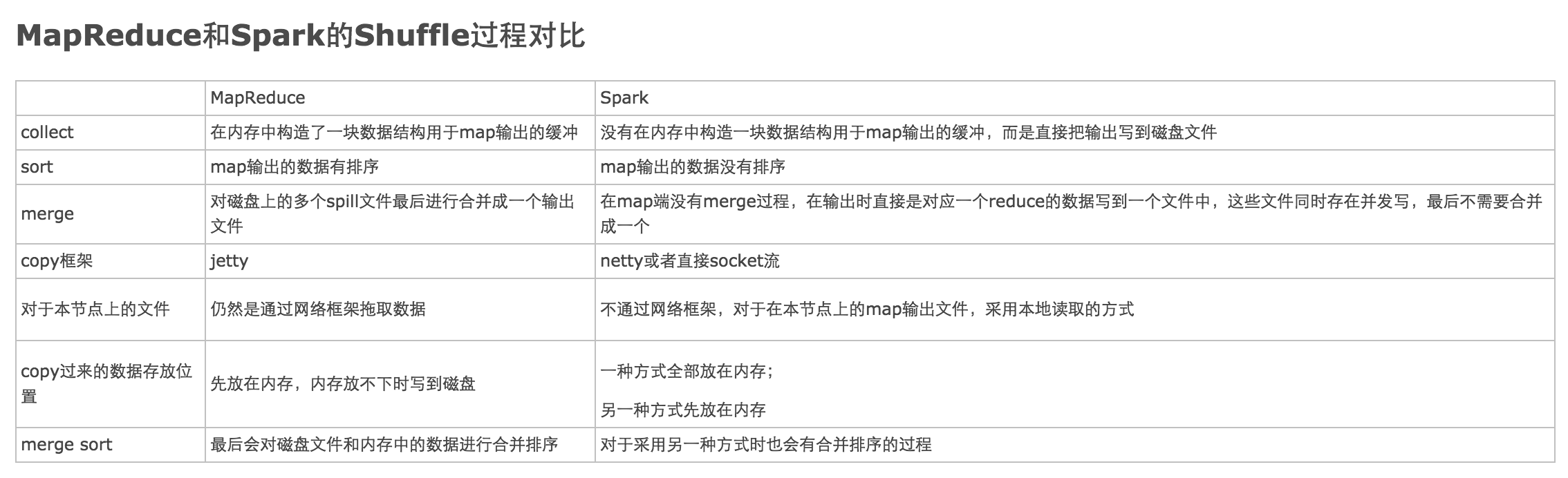
整体对比概念
Spark Shuffle 与MapReduce Shuffle的设计思想相同,但是实现细节优化方式不同。
1. 从逻辑角度来讲,Shuffle 过程就是一个 GroupByKey 的过程,两者没有本质区别。
只是 MapReduce 为了方便 GroupBy 存在于不同 partition 中的 key/value records,就提前对 key 进行排序。Spark 认为很多应用不需要对 key 排序,就默认没有在 GroupBy 的过程中对 key 排序。2. 从数据流角度讲,两者有差别。
MapReduce 只能从一个 Map Stage shuffle 数据,Spark 可以从多个 Map Stages shuffle 数据3 .Shuffle write/read 实现上有一些区别。
以前对 shuffle write/read 的分类是 sort-based 和 hash-based。MapReduce 可以说是 sort-based,shuffle write 和 shuffle read 过程都是基于key sorting 的 (buffering records + in-memory sort + on-disk external sorting)。早期的 Spark 是 hash-based,shuffle write 和 shuffle read 都使用 HashMap-like 的数据结构进行 aggregate (without key sorting)。但目前的 Spark 是两者的结合体,shuffle write 可以是 sort-based (only sort partition id, without key sorting),shuffle read 阶段可以是 hash-based。因此,目前 sort-based 和 hash-based 已经“你中有我,我中有你”,界限已经不那么清晰。4. 从数据 fetch 与数据计算的重叠粒度来讲,两者有细微区别。
MapReduce 是粗粒度,reducer fetch 到的 records 先被放到shuffle buffer中休息,当 shuffle buffer 快满时,才对它们进行 combine()。而 Spark 是细粒度,可以即时将 fetch 到的 record 与 HashMap 中相同 key 的 record 进行 aggregate。
解说:
1、MapReduce在Map阶段完成之后数据会被写入到内存中的一个环形缓冲区(后续的分区/分组/排序在这里完成);Spark的Map阶段完成之后直接输出到磁盘。
2、受第一步的影响,MapReduce输出的数据是有序的(针对单个Map数据来说);Spark的数据是无序的(可以使用RDD算子达到排序的效果)。
3、MapReduce缓冲区的数据处理完之后会spill到磁盘形成一个文件,文件数量达到阈值之后将会进行merge操作,将多个小文件合并为一个大文件;Spark没有merge过程,一个Map中如果有对应多个Reduce的数据,则直接写多个磁盘文件。
4、MapReduce全部通过网络来获得数据;对于本地数据Spark可以直接读取
1.5 宽依赖与窄依赖区别
RDD和它的父RDD的关系有两种类型:窄依赖和宽依赖
- 宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition,关系是一对多,父RDD的一个分区的数据去到子RDD的不同分区里面,会有shuffle的产生
- 窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个partition使用,是一对一的,也就是父RDD的一个分区去到了子RDD的一个分区中,这个过程没有shuffle产生
区分的标准就是看父RDD的一个分区的数据的流向,要是流向一个partition的话就是窄依赖,否则就是宽依赖,如图所示:
1.6 Spark RDD 原理
1. RDD是什么
RDD(Resilient Distributed Dataset)叫做分布式数据集,是spark中最基本的数据抽象,它代表一个不可变,可分区,里面的元素可以并行计算的集合
- Dataset:就是一个集合,用于存放数据的
- Destributed:分布式,可以并行在集群计算
- Resilient:表示弹性的,弹性表示
- RDD中的数据可以存储在内存或者磁盘中;
- RDD中的分区是可以改变的;
- A list of partitions:一个分区列表,RDD中的数据都存储在一个分区列表中
- A function for computing each split:作用在每一个分区中的函数
- A list of dependencies on other RDDs:一个RDD依赖于其他多个RDD,这个点很重要,RDD的容错机制就是依据这个特性而来的
- Optionally,a Partitioner for key-value RDDs(eg:to say that the RDD is hash-partitioned):可选的,针对于kv类型的RDD才有这个特性,作用是决定了数据的来源以及数据处理后的去向
- 可选项,数据本地性,数据位置最优
2. RDD操作
RDD创建后就可以在RDD上进行数据处理。RDD支持两种操作:转换(transformation),即从现有的数据集创建一个新的数据集;动作(action),即在数据集上进行计算后,返回一个值给Driver程序。
- 转换(transformation)
RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter() ,而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如 count() 和 first() 。Spark 对待转化操作和行动操作的方式很不一样,因此理解你正在进行的操作的类型是很重要的。如果对于一个特定的函数是属于转化操作还是行动操作感到困惑,你可以看看它的返回值类型:转化操作返回的是 RDD,而行动操作返回的是其他的数据类型。
RDD中所有的Transformation都是惰性的,也就是说,它们并不会直接计算结果。相反的它们只是记住了这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给Driver的Action时,这些Transformation才会真正运行。
#### map(func)**
返回一个新的分布式数据集,该数据集由每一个输入元素经过func函数转换后组成
#### **fitler(func)**
返回一个新的数据集,该数据集由经过func函数计算后返回值为true的输入元素组成
#### **flatMap(func)**
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(因此func返回一个序列,而不是单一元素)
#### **mapPartitions(func)**
类似于map,但独立地在RDD上每一个分片上运行,因此在类型为T的RDD上运行时,func函数类型必须是Iterator[T]=>Iterator[U]
#### **mapPartitionsWithSplit(func)**
类似于mapPartitons,但func带有一个整数参数表示分片的索引值。因此在类型为T的RDD上运行时,func函数类型必须是(Int,Iterator[T])=>Iterator[U]
#### **sample(withReplacement,fraction,seed)**
根据fraction指定的比例对数据进行采样,可以选择是否用随机数进行替换,seed用于随机数生成器种子
#### **union(otherDataSet)**
返回一个新数据集,新数据集是由原数据集和参数数据集联合而成
#### **distinct([numTasks])**
返回一个包含原数据集中所有不重复元素的新数据集
#### **groupByKey([numTasks])**
在一个(K,V)数据集上调用,返回一个(K,Seq[V])对的数据集。注意默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数来改变它
#### **reduceByKey(func,[numTasks])**
在一个(K,V)对的数据集上调用,返回一个(K,V)对的数据集,使用指定的reduce函数,将相同的key的值聚合到一起。与groupByKey类似,reduceByKey任务的个数是可以通过第二个可选参数来设置的
#### **sortByKey([[ascending],numTasks])**
在一个(K,V)对的数据集上调用,K必须实现Ordered接口,返回一个按照Key进行排序的(K,V)对数据集。升序或降序由ascending布尔参数决定
#### **join(otherDataset0,[numTasks])**
在类型为(K,V)和(K,W)数据集上调用,返回一个相同的key对应的所有元素在一起的(K,(V,W))数据集
#### **cogroup(otherDataset,[numTasks])**
在类型为(K,V)和(K,W)数据集上调用,返回一个(K,Seq[V],Seq[W])元祖的数据集。这个操作也可以称为groupwith
#### **cartesain(ohterDataset)**
笛卡尔积,在类型为T和U类型的数据集上调用,返回一个(T,U)对数据集(两两的元素对)- 动作(action)
#### **reduce(func)**
通过函数func(接收两个参数,返回一个参数)聚集数据集中的所有元素。这个功能必须可交换且可关联的,从而可以正确的并行运行
#### **collect()**
在驱动程序中,以数组形式返回数据集中的所有元素。通常在使用filter或者其他操作返回一个足够小的数据子集后再使用会比较有用
#### **count()**
返回数据集元素个数
#### **first()**
返回数据集第一个元素(类似于take(1))
#### **take(n)**
返回一个由数据集前n个元素组成的数组
注意 这个操作目前并非并行执行,而是由驱动程序计算所有的元素
#### **takeSample(withReplacement,num,seed)**
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否由随机数替换不足的部分,seed用户指定随机数生成器种子
#### **saveAsTextFile(path)**
将数据集的元素以textfile的形式保存到本地文件系统—HDFS或者任何其他Hadoop支持的文件系统。对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本行
#### **saveAsSequenceFile(path)**
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以是本地系统、HDFS或者任何其他的Hadoop支持的文件系统。这个只限于由key-value对组成,并实现了Hadoop的Writable接口,或者可以隐式的转换为Writable的RDD(Spark包括了基本类型转换,例如Int、Double、String等)
#### **countByKey()**
对(K,V)类型的RDD有效,返回一个(K,Int)对的map,表示每一个key对应的元素个数
#### **foreach(func)**
在数据集的每一个元素上,运行函数func进行更新。通常用于边缘效果,例如更新一个叠加器,或者和外部存储系统进行交互,如HBase3. RDD共享变量
在应用开发中,一个函数被传递给Spark操作(例如map和reduce),在一个远程集群上运行,它实际上操作的是这个函数用到的所有变量的独立拷贝。这些变量会被拷贝到每一台机器。通常看来,在任务之间中,读写共享变量显然不够高效。然而,Spark还是为两种常见的使用模式,提供了两种有限的共享变量:广播变量和累加器。
(1). 广播变量(Broadcast Variables)
– 广播变量缓存到各个节点的内存中,而不是每个 Task
– 广播变量被创建后,能在集群中运行的任何函数调用
– 广播变量是只读的,不能在被广播后修改
– 对于大数据集的广播, Spark 尝试使用高效的广播算法来降低通信成本
val broadcastVar = sc.broadcast(Array(1, 2, 3))方法参数中是要广播的变量
(2). 累加器
累加器只支持加法操作,可以高效地并行,用于实现计数器和变量求和。Spark 原生支持数值类型和标准可变集合的计数器,但用户可以添加新的类型。只有驱动程序才能获取累加器的值。
4. RDD缓存
Spark可以使用 persist 和 cache 方法将任意 RDD 缓存到内存、磁盘文件系统中。缓存是容错的,如果一个 RDD 分片丢失,可以通过构建它的 transformation自动重构。被缓存的 RDD 被使用的时,存取速度会被大大加速。一般的executor内存60%做 cache, 剩下的40%做task。
Spark中,RDD类可以使用cache() 和 persist() 方法来缓存。cache()是persist()的特例,将该RDD缓存到内存中。而persist可以指定一个StorageLevel。StorageLevel的列表可以在StorageLevel 伴生单例对象中找到。
Spark的不同StorageLevel ,目的满足内存使用和CPU效率权衡上的不同需求。我们建议通过以下的步骤来进行选择:
如果你的RDDs可以很好的与默认的存储级别(MEMORY_ONLY)契合,就不需要做任何修改了。这已经是CPU使用效率最高的选项,它使得RDDs的操作尽可能的快。
如果不行,试着使用MEMORY_ONLY_SER并且选择一个快速序列化的库使得对象在有比较高的空间使用率的情况下,依然可以较快被访问。
尽可能不要存储到硬盘上,除非计算数据集的函数,计算量特别大,或者它们过滤了大量的数据。否则,重新计算一个分区的速度,和与从硬盘中读取基本差不多快。
如果你想有快速故障恢复能力,使用复制存储级别(例如:用Spark来响应web应用的请求)。所有的存储级别都有通过重新计算丢失数据恢复错误的容错机制,但是复制存储级别可以让你在RDD上持续的运行任务,而不需要等待丢失的分区被重新计算。
如果你想要定义你自己的存储级别(比如复制因子为3而不是2),可以使用StorageLevel 单例对象的apply()方法。
在不会使用cached RDD的时候,及时使用unpersist方法来释放它。
1.7 RDD有哪几种创建方式
1) 使用程序中的集合创建rdd
2) 使用本地文件系统创建rdd
3) 使用hdfs创建rdd,
4) 基于数据库db创建rdd
5) 基于Nosql创建rdd,如hbase
6) 基于s3创建rdd,
7) 基于数据流,如socket创建rdd
1.8 Spark的RDD DataFrame和DataSet的区别
RDD的优点:
- 相比于传统的MapReduce框架,Spark在RDD中内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据。
- 面向对象编程,直接存储的java对象,类型转化也安全
RDD的缺点:
- 由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦
- 默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
DataFrame的优点:
结构化数据处理非常方便,支持Avro, CSV, elastic search, and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
有针对性的优化,如采用Kryo序列化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数,所以运行更快。
hive兼容,支持hql、udf等
DataFrame的缺点:
- 编译时不能类型转化安全检查,运行时才能确定是否有问题
- 对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
DateSet的优点:
DateSet整合了RDD和DataFrame的优点,支持结构化和非结构化数据
和RDD一样,支持自定义对象存储
和DataFrame一样,支持结构化数据的sql查询
采用堆外内存存储,gc友好
类型转化安全,代码友好
如此回答有3个坑(容易引起面试官追问):
1)Spark shuffle 与 MapReduce shuffle(或者Spark 与 MR 的区别)
2)Spark内存模型
3)对gc(垃圾回收)的了解
1.10 Spark 的通信机制
分布式的通信方式
- RPC
- RMI
- JMS
- EJB
- Web Serivice
通信框架Akka
Hadoop MR中的计算框架,jobTracker和TaskTracker间是由于通过heartbeat的方式来进行的通信和传递数据,会导致非常慢的执行速度,而Spark具有出色的高效的Akka和netty通信系统
1.11 Spark的数据容错机制
一般而言,对于分布式系统,数据集的容错性通常有两种方式:
1) 数据检查点(在Spark中对应Checkpoint机制)。
2) 记录数据的更新(在Spark中对应Lineage血统机制)。
对于大数据分析而言,数据检查点操作成本较高,需要通过数据中心的网络连接在机器之间复制庞大的数据集,而网络带宽往往比内存带宽低,同时会消耗大量存储资源。
Spark选择记录更新的方式。但更新粒度过细时,记录更新成本也不低。因此,RDD只支持粗粒度转换,即只记录单个块上执行的单个操作,然后将创建RDD的一系列变换序列记录下来,以便恢复丢失的分区。
Lineage(血统)机制
每个RDD除了包含分区信息外,还包含它从父辈RDD变换过来的步骤,以及如何重建某一块数据的信息,因此RDD的这种容错机制又称“血统”(Lineage)容错。Lineage本质上很类似于数据库中的重做日志(Redo Log),只不过这个重做日志粒度很大,是对全局数据做同样的重做以便恢复数据。
相比其他系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据Transformation操作(如filter、map、join等)。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新计算和恢复丢失的数据分区。但这种数据模型粒度较粗,因此限制了Spark的应用场景。所以可以说Spark并不适用于所有高性能要求的场景,但同时相比细颗粒度的数据模型,也带来了性能方面的提升。
RDD在Lineage容错方面采用如下两种依赖来保证容错方面的性能:
窄依赖(Narrow Dependeny):窄依赖是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。其中,1个父RDD分区对应1个子RDD分区,可以分为如下两种情况:
子RDD分区与父RDD分区一一对应(如map、filter等算子)。一个子RDD分区对应N个父RDD分区(如co-paritioned(协同划分)过的Join)。
宽依赖(Wide Dependency,源码中称为Shuffle Dependency):
宽依赖是指一个父RDD分区对应多个子RDD分区,可以分为如下两种情况:
一个父RDD对应所有子RDD分区(未经协同划分的Join)。
一个父RDD对应多个RDD分区(非全部分区)(如groupByKey)。
窄依赖与宽依赖关系如图3-10所示。
从图3-10可以看出对依赖类型的划分:根据父RDD分区是对应一个还是多个子RDD分区来区分窄依赖(父分区对应一个子分区)和宽依赖(父分区对应多个子分区)。如果对应多个,则当容错重算分区时,对于需要重新计算的子分区而言,只需要父分区的一部分数据,因此其余数据的重算就导致了冗余计算。
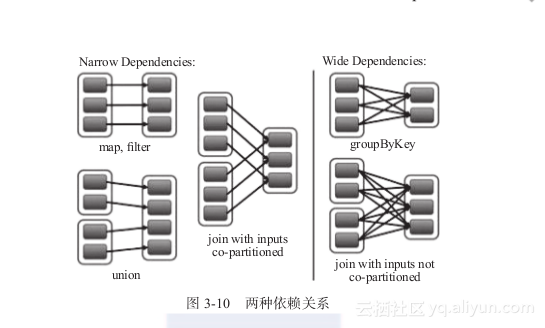
图3-10 两种依赖关系
对于宽依赖,Stage计算的输入和输出在不同的节点上,对于输入节点完好,而输出节点死机的情况,在通过重新计算恢复数据的情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上追溯其祖先看是否可以重试(这就是lineage,血统的意思),窄依赖对于数据的重算开销要远小于宽依赖的数据重算开销。
窄依赖和宽依赖的概念主要用在两个地方:一个是容错中相当于Redo日志的功能;另一个是在调度中构建DAG作为不同Stage的划分点(前面调度机制中已讲过)。
依赖关系在lineage容错中的应用总结如下:
1)窄依赖可以在某个计算节点上直接通过计算父RDD的某块数据计算得到子RDD对应的某块数据;宽依赖则要等到父RDD所有数据都计算完成,并且父RDD的计算结果进行hash并传到对应节点上之后,才能计算子RDD。
2)数据丢失时,对于窄依赖,只需要重新计算丢失的那一块数据来恢复;对于宽依赖,则要将祖先RDD中的所有数据块全部重新计算来恢复。所以在长“血统”链特别是有宽依赖时,需要在适当的时机设置数据检查点(checkpoint机制在下节讲述)。可见Spark在容错性方面要求对于不同依赖关系要采取不同的任务调度机制和容错恢复机制。
在Spark容错机制中,如果一个节点宕机了,而且运算属于窄依赖,则只要重算丢失的父RDD分区即可,不依赖于其他节点。而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。更深入地来说:在窄依赖关系中,当子RDD的分区丢失,重算其父RDD分区时,父RDD相应分区的所有数据都是子RDD分区的数据,因此不存在冗余计算。而在宽依赖情况下,丢失一个子RDD分区重算的每个父RDD的每个分区的所有数据并不是都给丢失的子RDD分区使用,其中有一部分数据对应的是其他不需要重新计算的子RDD分区中的数据,因此在宽依赖关系下,这样计算就会产生冗余开销,这也是宽依赖开销更大的原因。为了减少这种冗余开销,通常在Lineage血统链比较长,并且含有宽依赖关系的容错中使用Checkpoint机制设置检查点。
Checkpoint(检查点)机制
通过上述分析可以看出Checkpoint的本质是将RDD写入Disk来作为检查点。这种做法是为了通过lineage血统做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
1.13 Spark性能调优
1) 常用参数说明
--driver-memory 4g : driver内存大小,一般没有广播变量(broadcast)时,设置4g足够,如果有广播变量,视情况而定,可设置6G,8G,12G等均可
--executor-memory 4g : 每个executor的内存,正常情况下是4g足够,但有时处理大批量数据时容易内存不足,再多申请一点,如6G
--num-executors 15 : 总共申请的executor数目,普通任务十几个或者几十个足够了,若是处理海量数据如百G上T的数据时可以申请多一些,100,200等
--executor-cores 2 : 每个executor内的核数,即每个executor中的任务task数目,此处设置为2,即2个task共享上面设置的6g内存,每个map或reduce任务的并行度是executor数目*executor中的任务数
yarn集群中一般有资源申请上限,如,executor-memory*num-executors < 400G 等,所以调试参数时要注意这一点
—-spark.default.parallelism 200 : Spark作业的默认为500~1000个比较合适,如果不设置,spark会根据底层HDFS的block数量设置task的数量,这样会导致并行度偏少,资源利用不充分。该参数设为num-executors * executor-cores的2~3倍比较合适。
-- spark.storage.memoryFraction 0.6 : 设置RDD持久化数据在Executor内存中能占的最大比例。默认值是0.6
—-spark.shuffle.memoryFraction 0.2 : 设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2,如果shuffle聚合时使用的内存超出了这个20%的限制,多余数据会被溢写到磁盘文件中去,降低shuffle性能
—-spark.yarn.executor.memoryOverhead 1G : executor执行的时候,用的内存可能会超过executor-memory,所以会为executor额外预留一部分内存,spark.yarn.executor.memoryOverhead即代表这部分内存2) Spark常用编程建议
避免创建重复的RDD,尽量复用同一份数据。
尽量避免使用shuffle类算子,因为shuffle操作是spark中最消耗性能的地方,reduceByKey、join、distinct、repartition等算子都会触发shuffle操作,尽量使用map类的非shuffle算子
用aggregateByKey和reduceByKey替代groupByKey,因为前两个是预聚合操作,会在每个节点本地对相同的key做聚合,等其他节点拉取所有节点上相同的key时,会大大减少磁盘IO以及网络开销。
repartition适用于RDD[V], partitionBy适用于RDD[K, V]
mapPartitions操作替代普通map,foreachPartitions替代foreach
filter操作之后进行coalesce操作,可以减少RDD的partition数量
如果有RDD复用,尤其是该RDD需要花费比较长的时间,建议对该RDD做cache,若该RDD每个partition需要消耗很多内存,建议开启Kryo序列化机制(据说可节省2到5倍空间),若还是有比较大的内存开销,可将storage_level设置为MEMORY_AND_DISK_SER
尽量避免在一个Transformation中处理所有的逻辑,尽量分解成map、filter之类的操作
多个RDD进行union操作时,避免使用rdd.union(rdd).union(rdd).union(rdd)这种多重union,rdd.union只适合2个RDD合并,合并多个时采用SparkContext.union(Array(RDD)),避免union嵌套层数太多,导致的调用链路太长,耗时太久,且容易引发StackOverFlow
spark中的Group/join/XXXByKey等操作,都可以指定partition的个数,不需要额外使用repartition和partitionBy函数
尽量保证每轮Stage里每个task处理的数据量>128M
如果2个RDD做join,其中一个数据量很小,可以采用Broadcast Join,将小的RDD数据collect到driver内存中,将其BroadCast到另外以RDD中,其他场景想优化后面会讲
2个RDD做笛卡尔积时,把小的RDD作为参数传入,如BigRDD.certesian(smallRDD)
若需要Broadcast一个大的对象到远端作为字典查询,可使用多executor-cores,大executor-memory。若将该占用内存较大的对象存储到外部系统,executor-cores=1, executor-memory=m(默认值2g),可以正常运行,那么当大字典占用空间为size(g)时,executor-memory为2*size,executor-cores=size/m(向上取整)
如果对象太大无法BroadCast到远端,且需求是根据大的RDD中的key去索引小RDD中的key,可使用zipPartitions以hash join的方式实现,具体原理参考下一节的shuffle过程
如果需要在repartition重分区之后还要进行排序,可直接使用repartitionAndSortWithinPartitions,比分解操作效率高,因为它可以一边shuffle一边排序
3) shuffle性能优化
3.1 什么是shuffle操作
spark中的shuffle操作功能:将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行聚合或join操作,类似洗牌的操作。这些分布在各个存储节点上的数据重新打乱然后汇聚到不同节点的过程就是shuffle过程。
3.2 哪些操作中包含shuffle操作
RDD的特性是不可变的带分区的记录集合,Spark提供了Transformation和Action两种操作RDD的方式。Transformation是生成新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等;Action只是返回一个结果,包括collect,reduce,count,save,lookupKey等
Spark所有的算子操作中是否使用shuffle过程要看计算后对应多少分区:
- 若一个操作执行过程中,结果RDD的每个分区只依赖上一个RDD的同一个分区,即属于窄依赖,如map、filter、union等操作,这种情况是不需要进行shuffle的,同时还可以按照pipeline的方式,把一个分区上的多个操作放在同一个Task中进行
- 若结果RDD的每个分区需要依赖上一个RDD的全部分区,即属于宽依赖,如repartition相关操作(repartition,coalesce)、*ByKey操作(groupByKey,ReduceByKey,combineByKey、aggregateByKey等)、join相关操作(cogroup,join)、distinct操作,这种依赖是需要进行shuffle操作的
3.3 shuffle操作过程
shuffle过程分为shuffle write和shuffle read两部分
- shuffle write: 分区数由上一阶段的RDD分区数控制,shuffle write过程主要是将计算的中间结果按某种规则临时放到各个executor所在的本地磁盘上(当前stage结束之后,每个task处理的数据按key进行分类,数据先写入内存缓冲区,缓冲区满,溢写spill到磁盘文件,最终相同key被写入同一个磁盘文件)创建的磁盘文件数量=当前stage中task数量*下一个stage的task数量
- shuffle read:从上游stage的所有task节点上拉取属于自己的磁盘文件,每个read task会有自己的buffer缓冲,每次只能拉取与buffer缓冲相同大小的数据,然后聚合,聚合完一批后拉取下一批,边拉取边聚合。分区数由Spark提供的一些参数控制,如果这个参数值设置的很小,同时shuffle read的数据量很大,会导致一个task需要处理的数据非常大,容易发生JVM crash,从而导致shuffle数据失败,同时executor也丢失了,就会看到Failed to connect to host 的错误(即executor lost)。
shuffle过程中,各个节点会通过shuffle write过程将相同key都会先写入本地磁盘文件中,然后其他节点的shuffle read过程通过网络传输拉取各个节点上的磁盘文件中的相同key。这其中大量数据交换涉及到的网络传输和文件读写操作是shuffle操作十分耗时的根本原因
3.4 spark的shuffle类型
参数spark.shuffle.manager用于设置ShuffleManager的类型。Spark1.5以后,该参数有三个可选项:hash、sort和tungsten-sort。HashShuffleManager是Spark1.2以前的默认值,Spark1.2之后的默认值都是SortShuffleManager。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。
由于SortShuffleManager默认会对数据进行排序,因此如果业务需求中需要排序的话,使用默认的SortShuffleManager就可以;但如果不需要排序,可以通过bypass机制或设置HashShuffleManager避免排序,同时也能提供较好的磁盘读写性能。
HashShuffleManager流程:
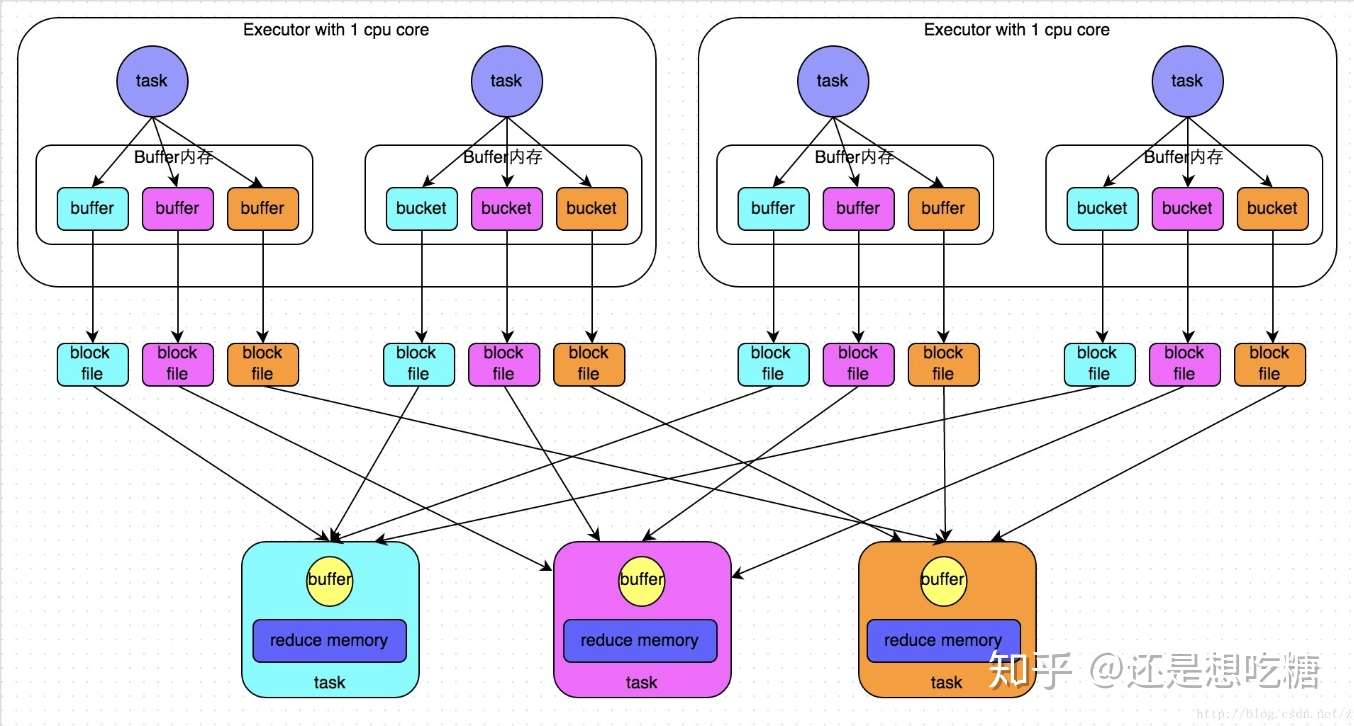
SortShuffleManager流程:
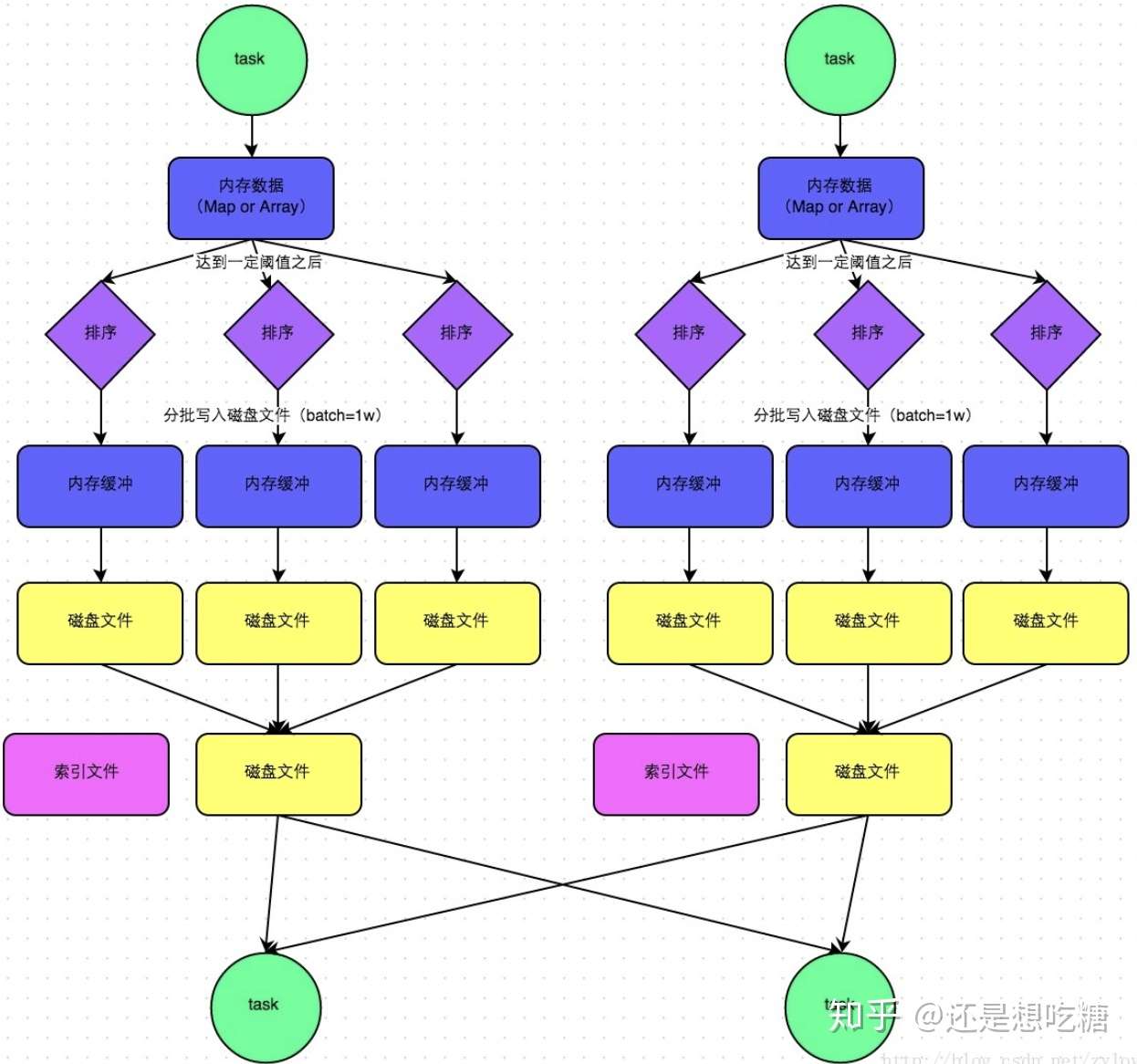
3.5 如何开启bypass机制
bypass机制通过参数spark.shuffle.sort.bypassMergeThreshold设置,默认值是200,表示当ShuffleManager是SortShuffleManager时,若shuffle read task的数量小于这个阈值(默认200)时,则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式写数据,但最后会将每个task产生的所有临时磁盘文件合并成一个文件,并创建索引文件。
这里给出的调优建议是,当使用SortShuffleManager时,如果的确不需要排序,可以将这个参数值调大一些,大于shuffle read task的数量。那么此时就会自动开启bypass机制,map-side就不会进行排序了,减少排序的性能开销,提升shuffle操作效率。但这种方式并没有减少shuffle write过程产生的磁盘文件数量,所以写的性能没有改变。
3.6 HashShuffleManager优化建议
如果使用HashShuffleManager,可以设置spark.shuffle.consolidateFiles参数。该参数默认为false,只有当使用HashShuffleManager且该参数设置为True时,才会开启consolidate机制,大幅度合并shuffle write过程产生的输出文件,对于shuffle read task 数量特别多的情况下,可以极大地减少磁盘IO开销,提升shuffle性能。参考社区同学给出的数据,consolidate性能比开启bypass机制的SortShuffleManager高出10% ~ 30%。
3.7 shuffle调优建议
除了上述的几个参数调优,shuffle过程还有一些参数可以提高性能:
- spark.shuffle.file.buffer : 默认32M,shuffle Write阶段写文件时的buffer大小,若内存资源比较充足,可适当将其值调大一些(如64M),减少executor的IO读写次数,提高shuffle性能
- spark.shuffle.io.maxRetries : 默认3次,Shuffle Read阶段取数据的重试次数,若shuffle处理的数据量很大,可适当将该参数调大。3.8 shuffle操作过程中的常见错误
SparkSQL中的shuffle错误:
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0
org.apache.spark.shuffle.FetchFailedException:Failed to connect to hostname/192.168.xx.xxx:50268RDD中的shuffle错误:
WARN TaskSetManager: Lost task 17.1 in stage 4.1 (TID 1386, spark050013): java.io.FileNotFoundException: /data04/spark/tmp/blockmgr-817d372f-c359-4a00-96dd-8f6554aa19cd/2f/temp_shuffle_e22e013a-5392-4edb-9874-a196a1dad97c (没有那个文件或目录)
FetchFailed(BlockManagerId(6083b277-119a-49e8-8a49-3539690a2a3f-S155, spark050013, 8533), shuffleId=1, mapId=143, reduceId=3, message=
org.apache.spark.shuffle.FetchFailedException: Error in opening FileSegmentManagedBuffer{file=/data04/spark/tmp/blockmgr-817d372f-c359-4a00-96dd-8f6554aa19cd/0e/shuffle_1_143_0.data, offset=997061, length=112503}处理shuffle类操作的注意事项:
- 减少shuffle数据量:在shuffle前过滤掉不必要的数据,只选取需要的字段处理
- 针对SparkSQL和DataFrame的join、group by等操作:可以通过 spark.sql.shuffle.partitions控制分区数,默认设置为200,可根据shuffle的量以及计算的复杂度提高这个值,如2000等
- RDD的join、group by、reduceByKey等操作:通过spark.default.parallelism控制shuffle read与reduce处理的分区数,默认为运行任务的core总数,官方建议为设置成运行任务的core的2~3倍
- 提高executor的内存:即spark.executor.memory的值
- 分析数据验证是否存在数据倾斜的问题:如空值如何处理,异常数据(某个key对应的数据量特别大)时是否可以单独处理,可以考虑自定义数据分区规则,如何自定义可以参考下面的join优化环节
4) join性能优化
Spark所有的操作中,join操作是最复杂、代价最大的操作,也是大部分业务场景的性能瓶颈所在。所以针对join操作的优化是使用spark必须要学会的技能。
spark的join操作也分为Spark SQL的join和Spark RDD的join。
4.1 Spark SQL 的join操作
4.1.1 Hash Join
Hash Join的执行方式是先将小表映射成Hash Table的方式,再将大表使用相同方式映射到Hash Table,在同一个hash分区内做join匹配。
hash join又分为broadcast hash join和shuffle hash join两种。其中Broadcast hash join,顾名思义,就是把小表广播到每一个节点上的内存中,大表按Key保存到各个分区中,小表和每个分区的大表做join匹配。这种情况适合一个小表和一个大表做join且小表能够在内存中保存的情况。如下图所示:
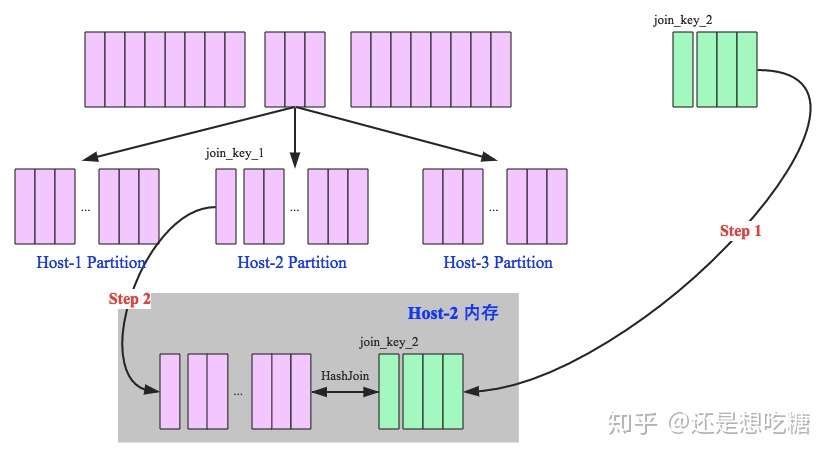
当Hash Join不能适用的场景就需要Shuffle Hash Join了,Shuffle Hash Join的原理是按照join Key分区,key相同的数据必然分配到同一分区中,将大表join分而治之,变成小表的join,可以提高并行度。执行过程也分为两个阶段:
- shuffle阶段:分别将两个表按照join key进行分区,将相同的join key数据重分区到同一节点
- hash join阶段:每个分区节点上的数据单独执行单机hash join算法
Shuffle Hash Join的过程如下图所示:
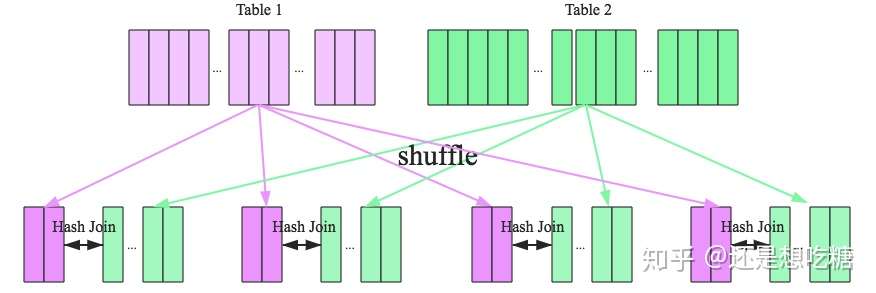
4.1.2 Sort-Merge Join
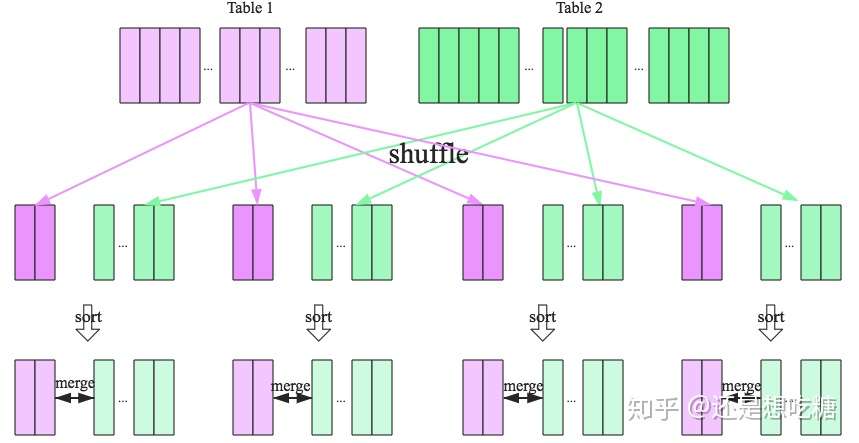
SparkSQL针对两张大表join的情况提供了全新的算法——Sort-merge join,整个过程分为三个步骤:
- Shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式进行处理
- sort阶段:对单个分区节点的两表数据,分别进行排序
- merge阶段:对排好序的两张分区表数据执行join操作。分别遍历两个有序序列,遇到相同的join key就merge输出,否则继续取更小一边的key,即合并两个有序列表的方式。
sort-merge join流程如下图所示。
4.2 Spark RDD的join操作
Spark的RDD join没有上面这么多的分类,但是面临的业务需求是一样的。如果是大表join小表的情况,则可以将小表声明为broadcast变量,使用map操作快速实现join功能,但又不必执行Spark core中的join操作。
如果是两个大表join,则必须依赖Spark Core中的join操作了。Spark RDD Join的过程可以自行阅读源码了解,这里只做一个大概的讲解。
spark的join过程中最核心的函数是cogroup方法,这个方法中会判断join的两个RDD所使用的partitioner是否一样,如果分区相同,即存在OneToOneDependency依赖,不用进行hash分区,可直接join;如果要关联的RDD和当前RDD的分区不一致时,就要对RDD进行重新hash分区,分到正确的分区中,即存在ShuffleDependency,需要先进行shuffle操作再join。因此提升join效率的一个思路就是使得两个RDD具有相同的partitioners。
所以针对Spark RDD的join操作的优化建议是:
- 如果需要join的其中一个RDD比较小,可以直接将其存入内存,使用broadcast hash join
- 在对两个RDD进行join操作之前,使其使用同一个partitioners,避免join操作的shuffle过程
- 如果两个RDD其一存在重复的key也会导致join操作性能变低,因此最好先进行key值的去重处理
4.3 数据倾斜优化
均匀数据分布的情况下,前面所说的优化建议就足够了。但存在数据倾斜时,仍然会有性能问题。主要体现在绝大多数task执行得都非常快,个别task执行很慢,拖慢整个任务的执行进程,甚至可能因为某个task处理的数据量过大而爆出OOM错误。
shuffle操作中需要将各个节点上相同的key拉取到某一个节点上的一个task处理,如果某个key对应的数据量特别大,就会发生数据倾斜。
4.3.1 分析数据分布
如果是Spark SQL中的group by、join语句导致的数据倾斜,可以使用SQL分析执行SQL中的表的key分布情况;如果是Spark RDD执行shuffle算子导致的数据倾斜,可以在Spark作业中加入分析Key分布的代码,使用countByKey()统计各个key对应的记录数。
4.3.2 数据倾斜的解决方案
这里参考美团技术博客中给出的几个方案。
1)针对hive表中的数据倾斜,可以尝试通过hive进行数据预处理,如按照key进行聚合,或是和其他表join,Spark作业中直接使用预处理后的数据。
2)如果发现导致倾斜的key就几个,而且对计算本身的影响不大,可以考虑过滤掉少数导致倾斜的key
3)设置参数spark.sql.shuffle.partitions,提高shuffle操作的并行度,增加shuffle read task的数量,降低每个task处理的数据量
4)针对RDD执行reduceByKey等聚合类算子或是在Spark SQL中使用group by语句时,可以考虑两阶段聚合方案,即局部聚合+全局聚合。第一阶段局部聚合,先给每个key打上一个随机数,接着对打上随机数的数据执行reduceByKey等聚合操作,然后将各个key的前缀去掉。第二阶段全局聚合即正常的聚合操作。
5)针对两个数据量都比较大的RDD/hive表进行join的情况,如果其中一个RDD/hive表的少数key对应的数据量过大,另一个比较均匀时,可以先分析数据,将数据量过大的几个key统计并拆分出来形成一个单独的RDD,得到的两个RDD/hive表分别和另一个RDD/hive表做join,其中key对应数据量较大的那个要进行key值随机数打散处理,另一个无数据倾斜的RDD/hive表要1对n膨胀扩容n倍,确保随机化后key值仍然有效。
6)针对join操作的RDD中有大量的key导致数据倾斜,对有数据倾斜的整个RDD的key值做随机打散处理,对另一个正常的RDD进行1对n膨胀扩容,每条数据都依次打上0~n的前缀。处理完后再执行join操作
5) 其他错误总结
(1) 报错信息
java.lang.OutOfMemory, unable to create new native thread
Caused by: java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:640) 解决方案:
上面这段错误提示的本质是Linux操作系统无法创建更多进程,导致出错,并不是系统的内存不足。因此要解决这个问题需要修改Linux允许创建更多的进程,就需要修改Linux最大进程数
(2)报错信息
由于Spark在计算的时候会将中间结果存储到/tmp目录,而目前linux又都支持tmpfs,其实就是将/tmp目录挂载到内存当中, 那么这里就存在一个问题,中间结果过多导致/tmp目录写满而出现如下错误
No Space Left on the device(Shuffle临时文件过多)
解决方案:
修改配置文件spark-env.sh,把临时文件引入到一个自定义的目录中去, 即:
export SPARK_LOCAL_DIRS=/home/utoken/datadir/spark/tmp
(3)报错信息
Worker节点中的work目录占用许多磁盘空间, 这些是Driver上传到worker的文件, 会占用许多磁盘空间
解决方案:
需要定时做手工清理work目录
(4)spark-shell提交Spark Application如何解决依赖库
解决方案:
利用–driver-class-path选项来指定所依赖的jar文件,注意的是–driver-class-path后如果需要跟着多个jar文件的话,jar文件之间使用冒号:来分割。
(5)内存不足或数据倾斜导致Executor Lost,shuffle fetch失败,Task重试失败等(spark-submit提交)
TaskSetManager: Lost task 1.0 in stage 6.0 (TID 100, 192.168.10.37): java.lang.OutOfMemoryError: Java heap space
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.37:57139 (size: 42.0 KB, free: 24.2 MB)
INFO BlockManagerInfo: Added broadcast_8_piece0 in memory on 192.168.10.38:53816 (size: 42.0 KB, free: 24.2 MB)
INFO TaskSetManager: Starting task 3.0 in stage 6.0 (TID 102, 192.168.10.37, ANY, 2152 bytes)解决方案:
增加worker内存,或者相同资源下增加partition数目,这样每个task要处理的数据变少,占用内存变少
如果存在shuffle过程,设置shuffle read阶段的并行数
2. SparkSQL
2.1 Spark SQL 的原理和运行机制
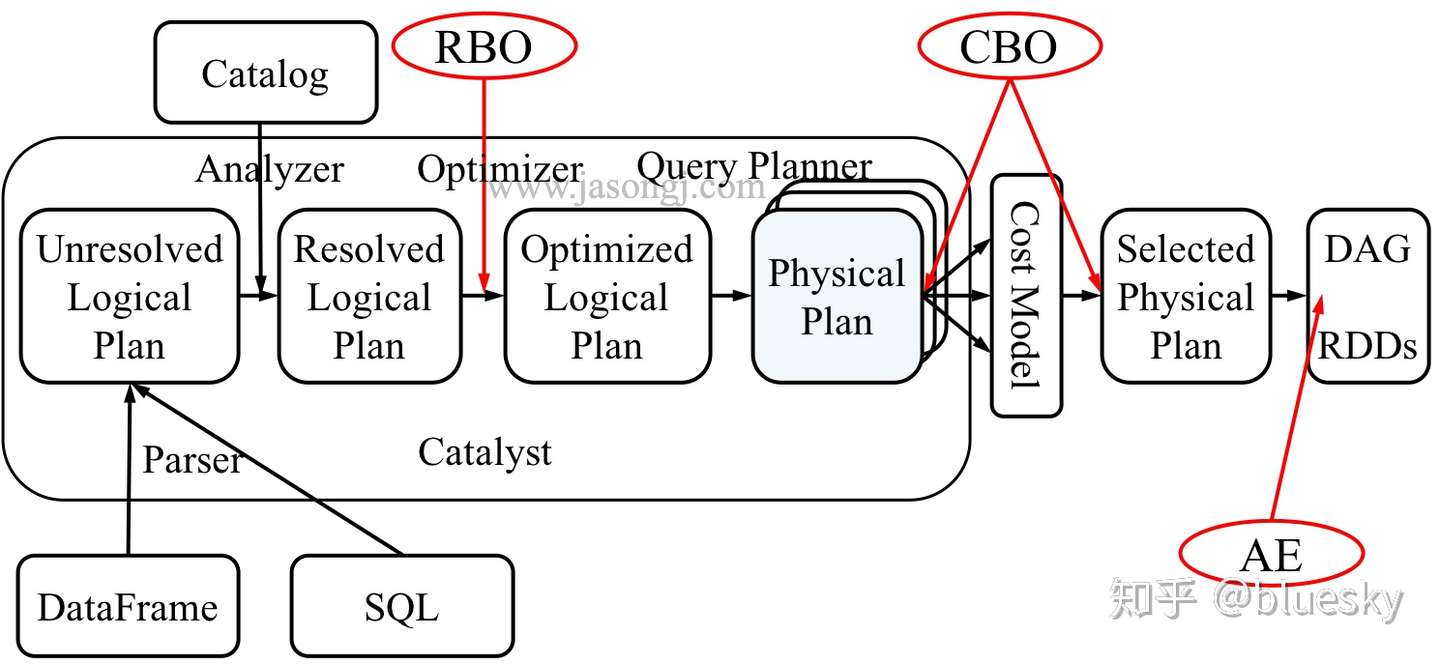
从上图可见,无论是直接使用 SQL 语句还是使用 DataFrame,都会经过如下步骤转换成 DAG 对 RDD 的操作
- Parser 解析 SQL,生成 Unresolved Logical Plan
- 由 Analyzer 结合 Catalog 信息生成 Resolved Logical Plan
- Optimizer根据预先定义好的规则对 Resolved Logical Plan 进行优化并生成 Optimized Logical Plan
- Query Planner 将 Optimized Logical Plan 转换成多个 Physical Plan
- CBO 根据 Cost Model 算出每个 Physical Plan 的代价并选取代价最小的 Physical Plan 作为最终的 Physical Plan
- Spark 以 DAG 的方法执行上述 Physical Plan
- 在执行 DAG 的过程中,Adaptive Execution 根据运行时信息动态调整执行计划从而提高执行效率
Parser
Spark SQL 使用 Antlr 进行记法和语法解析,并生成 UnresolvedPlan。
当用户使用 SparkSession.sql(sqlText : String) 提交 SQL 时,SparkSession 最终会调用 SparkSqlParser 的 parsePlan 方法。该方法分两步
- 使用 Antlr 生成的 SqlBaseLexer 对 SQL 进行词法分析,生成 CommonTokenStream
- 使用 Antlr 生成的 SqlBaseParser 进行语法分析,得到 LogicalPlan
Analyzer
从 Analyzer 的构造方法可见
Analyzer 持有一个 SessionCatalog 对象的引用
Analyzer 继承自 RuleExecutor[LogicalPlan],因此可对 LogicalPlan 进行转换
Optimizer
Spark SQL 目前的优化主要是基于规则的优化,即 RBO (Rule-based optimization)
- 每个优化以 Rule 的形式存在,每条 Rule 都是对 Analyzed Plan 的等价转换
- RBO 设计良好,易于扩展,新的规则可以非常方便地嵌入进 Optimizer
- RBO 目前已经足够好,但仍然需要更多规则来 cover 更多的场景
- 优化思路主要是减少参与计算的数据量以及计算本身的代价
PushdownPredicate
PushdownPredicate 是最常见的用于减少参与计算的数据量的方法。
SparkPlanner
得到优化后的 LogicalPlan 后,SparkPlanner 将其转化为 SparkPlan 即物理计划。
本例中由于 score 表数据量较小,Spark 使用了 BroadcastJoin。因此 score 表经过 Filter 后直接使用 BroadcastExchangeExec 将数据广播出去,然后结合广播数据对 people 表使用 BroadcastHashJoinExec 进行 Join。再经过 Project 后使用 HashAggregateExec 进行分组聚合。
至此,一条 SQL 从提交到解析、分析、优化以及执行的完整过程就介绍完毕。
2.3 Spark SQL 的优化策略
1)内存列式存储与内存缓存表
Spark SQL可以通过cacheTable将数据存储转换为列式存储,同时将数据加载到内存缓存。cacheTable相当于在分布式集群的内存物化视图,将数据缓存,这样迭代的或者交互式的查询不用再从HDFS读数据,直接从内存读取数据大大减少了I/O开销。列式存储的优势在于Spark SQL只需要读出用户需要的列,而不需要像行存储那样每次都将所有列读出,从而大大减少内存缓存数据量,更高效地利用内存数据缓存,同时减少网络传输和I/O开销。数据按照列式存储,由于是数据类型相同的数据连续存储,所以能够利用序列化和压缩减少内存空间的占用。
2)列存储压缩
为了减少内存和硬盘空间占用,Spark SQL采用了一些压缩策略对内存列存储数据进行压缩。Spark SQL的压缩方式要比Shark丰富很多,如它支持PassThrough、RunLengthEncoding、DictionaryEncoding、BooleanBitSet、IntDelta、LongDelta等多种压缩方式,这样能够大幅度减少内存空间占用、网络传输和I/O开销。
3)逻辑查询优化
SparkSQL在逻辑查询优化(见图8-4)上支持列剪枝、谓词下压、属性合并等逻辑查询优化方法。列剪枝为了减少读取不必要的属性列、减少数据传输和计算开销,在查询优化器进行转换的过程中会优化列剪枝。
下面介绍一个逻辑优化的例子。
SELECT Class FROM (SELECT ID,Name,Class FROM STUDENT ) S WHERE S.ID=1
Catalyst将原有查询通过谓词下压,将选择操作ID=1优先执行,这样过滤大部分数据,通过属性合并将最后的投影只做一次,最终保留Class属性列。
4)Join优化
Spark SQL深度借鉴传统数据库的查询优化技术的精髓,同时在分布式环境下调整和创新特定的优化策略。现在Spark SQL对Join进行了优化,支持多种连接算法,现在的连接算法已经比Shark丰富,而且很多原来Shark的元素也逐步迁移过来,如BroadcastHashJoin、BroadcastNestedLoopJoin、HashJoin、LeftSemiJoin,等等。
下面介绍其中的一个Join算法。
BroadcastHashJoin将小表转化为广播变量进行广播,这样避免Shuffle开销,最后在分区内做Hash连接。这里使用的就是Hive中Map Side Join的思想,同时使用DBMS中的Hash连接算法做连接。 随着Spark SQL的发展,未来会有更多的查询优化策略加入进来,同时后续Spark SQL会支持像Shark Server一样的服务端和JDBC接口,兼容更多的持久化层,如NoSQL、传统的DBMS等。一个强有力的结构化大数据查询引擎正在崛起。
3. SparkStreaming
3.1 原理剖析(源码级别)和运行机制
3.2 Spark Dstream 及其 API 操作
3.3 Spark Streaming 消费 Kafka 的两种方式
3.4 Spark 消费 Kafka 消息的 Offset 处理
3.5 窗口操作
4. SparkMlib
可实现聚类、分类、推荐等算法
三. Flink
- Flink 集群的搭建
- Flink 的架构原理
- Flink 的编程模型
- Flink 集群的 HA 配置
- Flink DataSet 和 DataSteam API
- 序列化
- Flink 累加器
- 状态 State 的管理和恢复
- 窗口和时间
- 并行度
- Flink 和消息中间件 Kafka 的结合
- Flink Table 和 SQL 的原理和用法
四. Kafka
1. Kafka 的设计
Kafka 将消息以 topic 为单位进行归纳
将向 Kafka topic 发布消息的程序成为 producers.
将预订 topics 并消费消息的程序成为 consumer.
Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker.
producers 通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
2. 数据传输的三种事务定义
数据传输的事务定义通常有以下三种级别:
(1)最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
(2)最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
(3)精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而
且仅仅被传输一次,这是大家所期望的
3. Kafka 判断一个节点是否活着两大条件
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连
接
(2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
4. Kafa consumer 是否可以消费指定分区消息?
Kafa consumer 消费消息时,向 broker 发出”fetch”请求去消费特定分区的消息,consumer
指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer 拥有
了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
5. Kafka 消息是采用 Pull 模式or Push 模式?
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消息推送到
consumer,也就是 pull 还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统
的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息
一些消息系统比如 Scribe 和 Apache Flume 采用了 push 模式,将消息推送到下游的
consumer。这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的
consumer 就不太好处理了。消息系统都致力于让 consumer 以最大的速率最快速的消费消
息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率时,
consumer 恐怕就要崩溃了。最终 Kafka 还是选取了传统的 pull 模式
Pull 模式的另外一个好处是 consumer 可以自主决定是否批量的从 broker 拉取数据。Push
模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条消息还
是缓存之后批量推送。如果为了避免 consumer 崩溃而采用较低的推送速率,将可能导致一
次只推送较少的消息而造成浪费。Pull 模式下,consumer 就可以根据自己的消费能力去决
定这些策略
Pull 有个缺点是,如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,
直到新消息到 t 达。为了避免这点,Kafka 有个参数可以让 consumer 阻塞知道新消息到达
(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
6. Kafka 存储在硬盘上的消息格式是什么?
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和 CRC32
校验码。
- 消息长度: 4 bytes (value: 1+4+n)
- 版本号: 1 byte
- CRC 校验码: 4 bytes
- 具体的消息: n bytes
7. Kafka 高效文件存储设计特点
(1).Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定
期清除或删除已经消费完文件,减少磁盘占用。
(2).通过索引信息可以快速定位 message 和确定 response 的最大大小。
(3).通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
(4).通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
8. Kafka 与传统消息系统之间有三个关键区别
(1).Kafka 持久化日志,这些日志可以被重复读取和无限期保留
(2).Kafka 是一个分布式系统:它以集群的方式运行,可以灵活伸缩,在内部通过复制数据
提升容错能力和高可用性
(3).Kafka 支持实时的流式处理
9. Kafka 创建 Topic 时如何将分区放置到不同的 Broker 中
- 副本因子不能大于 Broker 的个数;
- 第一个分区(编号为 0)的第一个副本放置位置是随机从 brokerList 选择的;
- 其他分区的第一个副本放置位置相对于第 0 个分区依次往后移。也就是如果我们有 5 个Broker,5 个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个Broker 上,依次类推;
- 剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的
10. Kafka 新建的分区会在哪个目录下创建
在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,
这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘
上用于提高读写性能。
当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。
如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个
目录下创建文件夹用于存放数据。
但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?
答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic
名+分区 ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就
是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁
盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
11. partition 的数据如何保存到硬盘
topic 中的多个 partition 以文件夹的形式保存到 broker,每个分区序号从 0 递增,
且消息有序
Partition 文件下有多个 segment(xxx.index,xxx.log)
segment 文件里的 大小和配置文件大小一致可以根据要求修改 默认为 1g
如果大小大于 1g 时,会滚动一个新的 segment 并且以上一个 segment 最后一条消息的偏移
量命名
12. kafka 的 ack 机制
request.required.acks 有三个值 0 1 -1
0:生产者不会等待 broker 的 ack,这个延迟最低但是存储的保证最弱当 server 挂掉的时候
就会丢数据
1:服务端会等待 ack 值 leader 副本确认接收到消息后发送 ack 但是如果 leader 挂掉后他
不确保是否复制完成新 leader 也会导致数据丢失
-1:同样在 1 的基础上 服务端会等所有的 follower 的副本受到数据后才会受到 leader 发出
的 ack,这样数据不会丢失
13. Kafka 的消费者如何消费数据
消费者每次消费数据的时候,消费者都会记录消费的物理偏移量(offset)的位置
等到下次消费时,他会接着上次位置继续消费
14. 消费者负载均衡策略
一个消费者组中的一个分片对应一个消费者成员,他能保证每个消费者成员都能访问,如
果组中成员太多会有空闲的成员
15. 数据有序
一个消费者组里它的内部是有序的
消费者组与消费者组之间是无序的
16. kafaka 生产数据时数据的分组策略
生产者决定数据产生到集群的哪个 partition 中
每一条消息都是以(key,value)格式
Key 是由生产者发送数据传入
所以生产者(key)决定了数据产生到集群的哪个 partition
五. 数据仓库
5.1 数仓概念相关
1. 数据仓库、数据集市、数据库之间的区别
数据仓库 :数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。是企业级的,能为整个企业各个部门的运行提供决策支持手段;
数据集市:则是一种微型的数据仓库,它通常有更少的数据,更少的主题区域,以及更少的历史数据,因此是部门级的,一般只能为某个局部范围内的管理人员服务,因此也称之为部门级数据仓库。
数据库:是一种软件,用来实现数据库逻辑过程,属于物理层;
数据仓库是数据库概念的升级,从数据量来说,数据仓库要比数据库更庞大德多,主要用于数据挖掘和数据分析,辅助领导做决策
只是数据库内的数据时限要远远的长于操作型环境中的数据时限。在操作型环境中一般只保存有60
90天的数据,而在数据仓库中则要需要保存较长时限的数据(例如:510年),以适应DSS进行趋势分析的要求。
2. OLAP、OLTP概念及用途
OLAP: 即
On-Line Analysis Processing在线分析处理。OLAP的特点:联机分析处理的主要特点,是直接仿照用户的多角度思考模式,预先为用户组建多维的数据模型,维指的是用户的分析角度。
OLTP: 即
On-Line Transaction Processing联机事务处理过程(OLTP)OLTP的特点:结构复杂、实时性要求高。
OLAP和OLTP区别
1、基本含义不同:OLTP是传统的关系型数据库的bai主要应用,主要是基本的、日常的事务处理,记du录即时的增、删、改、查,比如在银行存取一笔款,就是一个事务交易。OLAP即联机分析处理,是数据仓库的核心部心,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态报表系统。
2、实时性要求不同:OLTP实时性要求高,OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。OLAP的实时性要求不是很高,很多应用顶多是每天更新一下数据。
3、数据量不同:OLTP数据量不是很大,一般只读/写数十条记录,处理简单的事务。OLAP数据量大,因为OLAP支持的是动态查询,所以用户也许要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大。
4、用户和系统的面向性不同:OLTP是面向顾客的,用于事务和查询处理。OLAP是面向市场的,用于数据分析。
5、数据库设计不同:OLTP采用实体-联系ER模型和面向应用的数据库设计。OLAP采用星型或雪花模型和面向主题的数据库设计。

3. 事实表、维度表、拉链表概念及区别
- 事实表:事实表其实质就是通过各种维度和一些指标值得组合来确定一个事实的,比如通过时间维度,地域组织维度,指标值可以去确定在某时某地的一些指标值怎么样的事实。事实表的每一条数据都是几条维度表的数据和指标值交汇而得到的。
- 维度表:维度表可以看成是用户用来分析一个事实的窗口,它里面的数据应该是对事实的各个方面描述,比如时间维度表,它里面的数据就是一些日,周,月,季,年,日期等数据,维度表只能是事实表的一个分析角度。
- 拉链表:拉链表,它是一种维护历史状态,以及最新状态数据的一种表。拉链表也是分区表,有些不变的数据或者是已经达到状态终点的数据就会把它放在分区里面,分区字段一般为开始时间:start_date和结束时间:end_date。一般在该天有效的数据,它的end_date是大于等于该天的日期的。获取某一天全量的数据,可以通过表中的start_date和end_date来做筛选,选出固定某一天的数据。例如我想取截止到20190813的全量数据,其where过滤条件就是where start_date<=’20190813’ and end_date>=20190813。
4. 全量表、增量表、快照表概念及区别
- 全量表:全量表没有分区,表中的数据是前一天的所有数据,比如说今天是24号,那么全量表里面拥有的数据是23号的所有数据,每次往全量表里面写数据都会覆盖之前的数据,所以全量表不能记录历史的数据情况,只有截止到当前最新的、全量的数据。
- 增量表:增量表,就是记录每天新增数据的表,比如说,从24号到25号新增了那些数据,改变了哪些数据,这些都会存储在增量表的25号分区里面。上面说的快照表的25号分区和24号分区(都是t+1,实际时间分别对应26号和25号),它两的数据相减就是实际时间25号到26号有变化的、增加的数据,也就相当于增量表里面25号分区的数据。
- 快照表:那么要能查到历史数据情况又该怎么办呢?这个时候快照表就派上用途了,快照表是有时间分区的,每个分区里面的数据都是分区时间对应的前一天的所有全量数据,比如说当前数据表有3个分区,24号,25号,26号。其中,24号分区里面的数据就是从历史到23号的所有数据,25号分区里面的数据就是从历史到24号的所有数据,以此类推。
4. 什么叫维度和度量值
维度:说明数据,维度是指可指定不同值的对象的描述性属性或特征。例如,地理位置的维度可以包括“纬度”、“经度”或“城市名称”。“城市名称”维度的值可以为“旧金山”、“柏林”或“新加坡”。
度量:事实表和维度交叉汇聚的点,度量和维度构成OLAP的主要概念,这里面对于在事实表或者一个多维立方体里面存放的数值型的、连续的字段,就是度量。这符合上面的意思,有标准,一个度量字段肯定是统一单位,例如元、户数。如果一个度量字段,其中的度量值可能是欧元又有可能是美元,那这个度量可没法汇总。在统一计量单位下,对不同维度的描述。
5. 什么叫缓慢维度变化(Slowly Changing Dimensions,SCD)
维度建模的数据仓库中,有一个概念叫Slowly Changing Dimensions,中文一般翻译成缓慢变化维,经常被简写为SCD。缓慢变化维的提出是因为在现实世界中,维度的属性并不是静态的,它会随着时间的流失发生缓慢的变化。这种随时间发生变化的维度我们一般称之为缓慢变化维,并且把处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,有时也简称为处理SCD的问题。
处理缓慢变化维的方法通常分为三种方式:
- 第一种方式是直接覆盖原值。这样处理,最容易实现,但是没有保留历史数据,无法分析历史变化信息。第一种方式通常简称为“TYPE 1”。
- 第二种方式是添加维度行。这样处理,需要代理键的支持。实现方式是当有维度属性发生变化时,生成一条新的维度记录,主键是新分配的代理键,通过自然键可以和原维度记录保持关联。第二种方式通常简称为“TYPE 2”。
- 第三种方式是添加属性列。这种处理的实现方式是对于需要分析历史信息的属性添加一列,来记录该属性变化前的值,而本属性字段使用TYPE 1来直接覆盖。这种方式的优点是可以同时分析当前及前一次变化的属性值,缺点是只保留了最后一次变化信息。第三种方式通常简称为“TYPE 3”。
5.2 数仓分层设计
1. 数据仓库分为4层:
- ODS层 (原始数据层) BDM
- DWD层 (明细数据层) FDM
- DWS层 (服务数据层) GDM ADM
- ADS层 (数据应用层) APP
2. 各层主要负责职责
ODS层(原始数据层):存放原始数据,直接加载原始日志、数据,数据保存原貌不做处理。
DWD层(明细数据层):结构与粒度原始表保持一致,对ODS层数据进行清洗(去除空值、脏数据、超过极限范围的数据)
DWS层 (服务数据层):以DWD为基础,进行轻度汇总
ADS层 (数据应用层):为各种统计报表提供数据
3. **为什么要分层?**
空间换时间:通过建设多层次的数据模型供用户使用,避免用户直接使用操作型数据,可以更高效的访问数据
把复杂问题简单化:一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复
便于处理业务的变化:随着业务的变化,只需要调整底层的数据,对应用层对业务的调整零感知
4. 数仓中每层表的建模?怎么建模?
(1)ODS: 特点是保持原始数据的原貌,不作修改!
原始数据怎么建模,ODS就怎么建模!举例: 用户行为数据特征是一条记录就是一行!
ODS层表(line string) 业务数据,参考Sqoop导入的数据类型进行建模!
(2)DWD层:特点从ODS层,将数据进行ETL(清洗),轻度聚合,再展开明细!
- 在展开明细时,对部分维度表进行降维操作
例如:将商品一二三级分类表,sku商品表,spu商品表,商品品牌表合并汇总为一张维度表!
- 对事实表,参考星型模型的建模策略,按照选择业务过程→声明粒度→确认维度→确认事实思路进行建模
选择业务过程: 选择感兴趣的事实表
声明粒度: 选择最细的粒度!可以由最细的粒度通过聚合的方式得到粗粒度!
确认维度: 根据3w原则确认维度,挑选自己感兴趣的维度
确认事实: 挑选感兴趣的度量字段,一般是从事实表中选取!
- DWS层: 根据业务需求进行分主题建模!一般是建宽表!
- DWT层: 根据业务需求进行分主题建模!一般是建宽表!
- ADS层: 根据业务需求进行建模!
5.3 数仓建模
1. 维度建模概念、类型、过程
维度建模:维度建模是一种将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文。度量是常常是以数值形式出现,事实周围有上下文包围着,这种上下文被直观地分成独立的逻辑块,称之为维度。它与实体-关系建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
维度建模过程:确定业务流程->确定粒度->确定纬度->确定事实
建模四步走:
1.选取要建模的业务处理流程
关注业务处理流程,而不是业务部门!
2.定义业务处理的粒度
“如何描述事实表的单个行?”
3.选定用于每个事实表行的维度
常见维度包括日期、产品等
4.确定用于形成每个事实表行的数字型事实
典型的事实包括订货量、支出额这样的可加性数据
2. 星型模型和雪花模型概念、区别
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型,

星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,
如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。

雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 “ 层次 “ 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。
它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率(空间换易用与效率)。
1.数据优化
雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。
相比较而言,星形模型实用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
2.业务模型
主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID将是Account_dimension的一个外键。
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
3.性能
第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将Advertiser的维度表和事实表连接即可。
4.ETL
雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。
星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
总结
通过上面的对比,我们可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。而雪花模型在关系型数据库中如MySQL,Oracle中非常常见,尤其像电商的数据库表。在数据仓库中雪花模型的应用场景比较少,但也不是没有,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的。
5.4 数仓使用经验
3. 数据仓库系统的数据质量如何保证?方案?
数据质量评估
完整性
准确性
及时性
一致性
4. 如何实现增量抽取?
(主要采用时间戳方式,提供数据抽取和处理的性能)
5. 常见的数据治理方案
1)数据压缩
2)小文件合并
3)冷数据处理
六. 数据库
6.1 基本概念
1. 主键、外键、超键、候选键
超键:在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:是最小超键,即没有冗余元素的超键。
主键:数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
外键:在一个表中存在的另一个表的主键称此表的外键。
2. 为什么用自增列作为主键
如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、
如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、
如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
3. 触发器的作用?
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的。它可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
4. 什么是存储过程?用什么来调用?
存储过程是一个预编译的SQL语句,优点是允许模块化的设计,就是说只需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
调用:
1)可以用一个命令对象来调用存储过程。
2)可以供外部程序调用,比如:java程序。
5. 存储过程的优缺点?
优点:
1)存储过程是预编译过的,执行效率高。
2)存储过程的代码直接存放于数据库中,通过存储过程名直接调用,减少网络通讯。
3)安全性高,执行存储过程需要有一定权限的用户。
4)存储过程可以重复使用,可减少数据库开发人员的工作量。
缺点:移植性差
6. 存储过程与函数的区别

7. 什么叫视图?游标是什么?
视图:
是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改会影响基本表。它使得我们获取数据更容易,相比多表查询。
游标:
是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集的当前行检索一行或多行。可以对结果集当前行做修改。一般不使用游标,但是需要逐条处理数据的时候,游标显得十分重要。
8. 视图的优缺点
优点:
1对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。
2)用户通过简单的查询可以从复杂查询中得到结果。
3)维护数据的独立性,试图可从多个表检索数据。
4)对于相同的数据可产生不同的视图。
缺点:
性能:查询视图时,必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,那么就无法更改数据
9. drop、truncate、 delete区别
最基本:
- drop直接删掉表。
- truncate删除表中数据,再插入时自增长id又从1开始。
- delete删除表中数据,可以加where字句。
(1) DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6) truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7) delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8) truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚。
(9) 在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:?truncate table 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。
(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
10. 什么是临时表,临时表什么时候删除?
临时表可以手动删除:
DROP TEMPORARY TABLE IF EXISTS temp_tb;临时表只在当前连接可见,当关闭连接时,MySQL会自动删除表并释放所有空间。因此在不同的连接中可以创建同名的临时表,并且操作属于本连接的临时表。
创建临时表的语法与创建表语法类似,不同之处是增加关键字TEMPORARY,如:
CREATE TEMPORARY TABLE tmp_table (
NAME VARCHAR (10) NOT NULL,
time date NOT NULL
);select * from tmp_table;
11. 非关系型数据库和关系型数据库区别,优势比较?
非关系型数据库的优势:
- 性能:NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
- 可扩展性:同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
- 复杂查询:可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
- 事务支持:使得对于安全性能很高的数据访问要求得以实现。
其他:
1.对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
2.NOSQL数据库慢慢开始具备SQL数据库的一些复杂查询功能,比如MongoDB。
3.对于事务的支持也可以用一些系统级的原子操作来实现例如乐观锁之类的方法来曲线救国,比如Redis set nx。
12. 数据库范式,根据某个场景设计数据表?
第一范式:(确保每列保持原子性)所有字段值都是不可分解的原子值。
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式,如下表所示。
上表所示的用户信息遵循了第一范式的要求,这样在对用户使用城市进行分类的时候就非常方便,也提高了数据库的性能。第二范式:(确保表中的每列都和主键相关)在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键。第三范式:(确保每列都和主键列直接相关,而不是间接相关) 数据表中的每一列数据都和主键直接相关,而不能间接相关。
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。BCNF:符合3NF,并且,主属性不依赖于主属性。
若关系模式属于第二范式,且每个属性都不传递依赖于键码,则R属于BC范式。
通常BC范式的条件有多种等价的表述:每个非平凡依赖的左边必须包含键码;每个决定因素必须包含键码。
BC范式既检查非主属性,又检查主属性。当只检查非主属性时,就成了第三范式。满足BC范式的关系都必然满足第三范式。
还可以这么说:若一个关系达到了第三范式,并且它只有一个候选码,或者它的每个候选码都是单属性,则该关系自然达到BC范式。
一般,一个数据库设计符合3NF或BCNF就可以了。第四范式:要求把同一表内的多对多关系删除。
第五范式:从最终结构重新建立原始结构。
13. 什么是 内连接、外连接、交叉连接、笛卡尔积等?
内连接: 只连接匹配的行
左外连接: 包含左边表的全部行(不管右边的表中是否存在与它们匹配的行),以及右边表中全部匹配的行
右外连接: 包含右边表的全部行(不管左边的表中是否存在与它们匹配的行),以及左边表中全部匹配的行
例如1:
SELECT a.,b. FROM luntan LEFT JOIN usertable as b ON a.username=b.username例如2:
SELECT a.,b. FROM city as a FULL OUTER JOIN user as b ON a.username=b.username全外连接: 包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行。
交叉连接: 生成笛卡尔积-它不使用任何匹配或者选取条件,而是直接将一个数据源中的每个行与另一个数据源的每个行都一一匹配
例如:
SELECT type,pub_name FROM titles CROSS JOIN publishers ORDER BY type注意:
很多公司都只是考察是否知道其概念,但是也有很多公司需要不仅仅知道概念,还需要动手写sql,一般都是简单的连接查询,具体关于连接查询的sql练习,参见以下链接:
14. varchar和char的使用场景?
1.char的长度是不可变的,而varchar的长度是可变的。
定义一个char[10]和varchar[10]。
如果存进去的是‘csdn’,那么char所占的长度依然为10,除了字符‘csdn’外,后面跟六个空格,varchar就立马把长度变为4了,取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要的。2.char的存取数度还是要比varchar要快得多,因为其长度固定,方便程序的存储与查找。
char也为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可谓是以空间换取时间效率。
varchar是以空间效率为首位。3.char的存储方式是:对英文字符(ASCII)占用1个字节,对一个汉字占用两个字节。
varchar的存储方式是:对每个英文字符占用2个字节,汉字也占用2个字节。4.两者的存储数据都非unicode的字符数据。
15. SQL语言分类
SQL语言共分为四大类:
- 数据查询语言DQL
- 数据操纵语言DML
- 数据定义语言DDL
- 数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE子句组成的查询块:
SELECT
FROM
WHERE2 .数据操纵语言DML
数据操纵语言DML主要有三种形式:
- 插入:INSERT
- 更新:UPDATE
- 删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象—–表、视图、索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER表 视图 索引 同义词 簇
DDL操作是隐性提交的!不能rollback
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
- GRANT:授权。
- ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。回滚—ROLLBACK;回滚命令使数据库状态回到上次最后提交的状态。其格式为:
SQL>ROLLBACK;- COMMIT [WORK]:提交。
在数据库的插入、删除和修改操作时,只有当事务在提交到数据
库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看
到所做的事情,别人只有在最后提交完成后才可以看到。
提交数据有三种类型:显式提交、隐式提交及自动提交。下面分
别说明这三种类型。(1) 显式提交
用COMMIT命令直接完成的提交为显式提交。其格式为:
SQL>COMMIT;(2) 隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令是:
ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,
EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。(3) 自动提交
若把AUTOCOMMIT设置为ON,则在插入、修改、删除语句执行后,
系统将自动进行提交,这就是自动提交。其格式为:
SQL>SET AUTOCOMMIT ON;
16. like %和-的区别
通配符的分类:
%百分号通配符:表示任何字符出现任意次数(可以是0次).
_下划线通配符:表示只能匹配单个字符,不能多也不能少,就是一个字符.
like操作符: LIKE作用是指示mysql后面的搜索模式是利用通配符而不是直接相等匹配进行比较.
注意: 如果在使用like操作符时,后面的没有使用通用匹配符效果是和=一致的,SELECT * FROM products WHERE products.prod_name like ‘1000’;
只能匹配的结果为1000,而不能匹配像JetPack 1000这样的结果.
- %通配符使用: 匹配以”yves”开头的记录:(包括记录”yves”) SELECT FROM products WHERE products.prod_name like ‘yves%’;
匹配包含”yves”的记录(包括记录”yves”) SELECT FROM products WHERE products.prod_name like ‘%yves%’;
匹配以”yves”结尾的记录(包括记录”yves”,不包括记录”yves “,也就是yves后面有空格的记录,这里需要注意) SELECT * FROM products WHERE products.prod_name like ‘%yves’;- 通配符使用: SELECT *FROM products WHERE products.prod_name like ‘_yves’; 匹配结果为: 像”yyves”这样记录.
SELECT\ FROM products WHERE products.prod*name like ‘yves**’; 匹配结果为: 像”yvesHe”这样的记录.(一个下划线只能匹配一个字符,不能多也不能少)注意事项:
- 注意大小写,在使用模糊匹配时,也就是匹配文本时,mysql是可能区分大小的,也可能是不区分大小写的,这个结果是取决于用户对MySQL的配置方式.如果是区分大小写,那么像YvesHe这样记录是不能被”yves__”这样的匹配条件匹配的.
- 注意尾部空格,”%yves”是不能匹配”heyves “这样的记录的.
- 注意NULL,%通配符可以匹配任意字符,但是不能匹配NULL,也就是说SELECT * FROM products WHERE products.prod_name like ‘%;是匹配不到products.prod_name为NULL的的记录.
技巧与建议:
正如所见, MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。这里给出一些使用通配符要记住的技巧。
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该 使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用 在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起 来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数.
参考博文:https://blog.csdn.net/u011479200/article/details/78513632
17. count(*)、count(1)、count(column)的区别
- count(*)对行的数目进行计算,包含NULL
- count(column)对特定的列的值具有的行数进行计算,不包含NULL值。
- count()还有一种使用方式,count(1)这个用法和count(*)的结果是一样的。
性能问题:
1.任何情况下SELECT COUNT(*) FROM tablename是最优选择;
2.尽量减少SELECT COUNT(*) FROM tablename WHERE COL = ‘value’ 这种查询;
3.杜绝SELECT COUNT(COL) FROM tablename WHERE COL2 = ‘value’ 的出现。
- 如果表没有主键,那么count(1)比count(*)快。
- 如果有主键,那么count(主键,联合主键)比count(*)快。
- 如果表只有一个字段,count(*)最快。
count(1)跟count(主键)一样,只扫描主键。count(*)跟count(非主键)一样,扫描整个表。明显前者更快一些。
18. 最左前缀原则
多列索引:
ALTER TABLE people ADD INDEX lname_fname_age (lame,fname,age);
为了提高搜索效率,我们需要考虑运用多列索引,由于索引文件以B-Tree格式保存,所以我们不用扫描任何记录,即可得到最终结果。
注:在mysql中执行查询时,只能使用一个索引,如果我们在lname,fname,age上分别建索引,执行查询时,只能使用一个索引,mysql会选择一个最严格(获得结果集记录数最少)的索引。
最左前缀原则:顾名思义,就是最左优先,上例中我们创建了lname_fname_age多列索引,相当于创建了(lname)单列索引,(lname,fname)组合索引以及(lname,fname,age)组合索引。
6.2 索引
1. 什么是索引?
何为索引:
数据库索引,是数据库管理系统中一个排序的数据结构,索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
2. 索引的作用?它的优点缺点是什么?
索引作用:
协助快速查询、更新数据库表中数据。
为表设置索引要付出代价的:
创建索引可以大大提高系统的性能(优点):
1.通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
2.可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
3.可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
4.在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
5.通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
增加索引也有许多不利的方面(缺点):
1.创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
2.索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
4. 哪些列适合建立索引、哪些不适合建索引?
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。
一般来说,应该在这些列上创建索引:
(1)在经常需要搜索的列上,可以加快搜索的速度;
(2)在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
(3)在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
(4)在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
(5)在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
(6)在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
对于有些列不应该创建索引:
(1)对于那些在查询中很少使用或者参考的列不应该创建索引。
这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
(2)对于那些只有很少数据值的列也不应该增加索引。
这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
(3)对于那些定义为text, image和bit数据类型的列不应该增加索引。
这是因为,这些列的数据量要么相当大,要么取值很少。
(4)当修改性能远远大于检索性能时,不应该创建索引。
这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
5. 什么样的字段适合建索引
唯一、不为空、经常被查询的字段
6.MySQL B+Tree索引和Hash索引的区别?
Hash索引和B+树索引的特点:
- Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位;
- B+树索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问;
为什么不都用Hash索引而使用B+树索引?
- Hash索引仅仅能满足”=”,”IN”和””查询,不能使用范围查询,因为经过相应的Hash算法处理之后的Hash值的大小关系,并不能保证和Hash运算前完全一样;
- Hash索引无法被用来避免数据的排序操作,因为Hash值的大小关系并不一定和Hash运算前的键值完全一样;
- Hash索引不能利用部分索引键查询,对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用;
- Hash索引在任何时候都不能避免表扫描,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要回表查询数据;
- Hash索引遇到大量Hash值相等的情况后性能并不一定就会比B+树索引高。
补充:
1.MySQL中,只有HEAP/MEMORY引擎才显示支持Hash索引。
2.常用的InnoDB引擎中默认使用的是B+树索引,它会实时监控表上索引的使用情况,如果认为建立哈希索引可以提高查询效率,则自动在内存中的“自适应哈希索引缓冲区”建立哈希索引(在InnoDB中默认开启自适应哈希索引),通过观察搜索模式,MySQL会利用index key的前缀建立哈希索引,如果一个表几乎大部分都在缓冲池中,那么建立一个哈希索引能够加快等值查询。
B+树索引和哈希索引的明显区别是:3.如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
4.如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
同理,哈希索引没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);5.哈希索引也不支持多列联合索引的最左匹配规则;
6.B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在所谓的哈希碰撞问题。
7.在大多数场景下,都会有范围查询、排序、分组等查询特征,用B+树索引就可以了。
7. B树和B+树的区别
- B树,每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为nul,叶子结点不包含任何关键字信息。
- B+树,所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接,所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。 (而B 树的非终节点也包含需要查找的有效信息)


8. 为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?
1.B+的磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
2.B+tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
9. 聚集索引和非聚集索引区别?
聚合索引(clustered index):
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
聚集索引类似于新华字典中用拼音去查找汉字,拼音检索表于书记顺序都是按照a~z排列的,就像相同的逻辑顺序于物理顺序一样,当你需要查找a,ai两个读音的字,或是想一次寻找多个傻(sha)的同音字时,也许向后翻几页,或紧接着下一行就得到结果了。非聚合索引(nonclustered index):
非聚集索引指定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
非聚集索引类似在新华字典上通过偏旁部首来查询汉字,检索表也许是按照横、竖、撇来排列的,但是由于正文中是a~z的拼音顺序,所以就类似于逻辑地址于物理地址的不对应。同时适用的情况就在于分组,大数目的不同值,频繁更新的列中,这些情况即不适合聚集索引。根本区别:
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
6.3 事务
1. 什么是事务?
事务是对数据库中一系列操作进行统一的回滚或者提交的操作,主要用来保证数据的完整性和一致性。
2. 事务四大特性(ACID)原子性、一致性、隔离性、持久性?
原子性(Atomicity):
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。一致性(Consistency):
事务开始前和结束后,数据库的完整性约束没有被破坏。比如A向B转账,不可能A扣了钱,B却没收到。隔离性(Isolation):
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。持久性(Durability):
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
3. 事务的并发?事务隔离级别,每个级别会引发什么问题,MySQL默认是哪个级别?
从理论上来说, 事务应该彼此完全隔离, 以避免并发事务所导致的问题,然而, 那样会对性能产生极大的影响, 因为事务必须按顺序运行, 在实际开发中, 为了提升性能, 事务会以较低的隔离级别运行, 事务的隔离级别可以通过隔离事务属性指定。
事务的并发问题1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
3、幻读:幻读解决了不重复读,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。
例如:事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作 这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。 而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有跟没有修改一样,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。事务的隔离级别
读未提交:另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据脏读
不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果因此本事务先后两次读到的数据结果会不一致。
可重复读:在同一个事务里,SELECT的结果是事务开始时时间点的状态,因此,同样的SELECT操作读到的结果会是一致的。但是,会有幻读现象
串行化:最高的隔离级别,在这个隔离级别下,不会产生任何异常。并发的事务,就像事务是在一个个按照顺序执行一样

特别注意:
MySQL默认的事务隔离级别为repeatable-read
MySQL 支持 4 中事务隔离级别.
事务的隔离级别要得到底层数据库引擎的支持, 而不是应用程序或者框架的支持.
Oracle 支持的 2 种事务隔离级别:READ_COMMITED , SERIALIZABLE
SQL规范所规定的标准,不同的数据库具体的实现可能会有些差异
MySQL中默认事务隔离级别是“可重复读”时并不会锁住读取到的行
事务隔离级别:未提交读时,写数据只会锁住相应的行。
事务隔离级别为:可重复读时,写数据会锁住整张表。
事务隔离级别为:串行化时,读写数据都会锁住整张表。
隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大,鱼和熊掌不可兼得啊。对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读取,而且具有较好的并发性能。尽管它会导致不可重复读、幻读这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
4. 事务传播行为
1.PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,该设置是最常用的设置。
2.PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
3.PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
4.PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
5.PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
6.PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
7.PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
5. 嵌套事务
什么是嵌套事务?
嵌套是子事务套在父事务中执行,子事务是父事务的一部分,在进入子事务之前,父事务建立一个回滚点,叫save point,然后执行子事务,这个子事务的执行也算是父事务的一部分,然后子事务执行结束,父事务继续执行。重点就在于那个save point。看几个问题就明了了:
如果子事务回滚,会发生什么?
父事务会回滚到进入子事务前建立的save point,然后尝试其他的事务或者其他的业务逻辑,父事务之前的操作不会受到影响,更不会自动回滚。
如果父事务回滚,会发生什么?
父事务回滚,子事务也会跟着回滚!为什么呢,因为父事务结束之前,子事务是不会提交的,我们说子事务是父事务的一部分,正是这个道理。那么:
事务的提交,是什么情况?
是父事务先提交,然后子事务提交,还是子事务先提交,父事务再提交?答案是第二种情况,还是那句话,子事务是父事务的一部分,由父事务统一提交。
参考文章:https://blog.csdn.net/liangxw1/article/details/51197560
6.4 存储引擎
1. MySQL常见的三种存储引擎(InnoDB、MyISAM、MEMORY)的区别?
两种存储引擎的大致区别表现在:
1.InnoDB支持事务,MyISAM不支持, 这一点是非常之重要。事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而MyISAM就不可以了。
2.MyISAM适合查询以及插入为主的应用。
3.InnoDB适合频繁修改以及涉及到安全性较高的应用。
4.InnoDB支持外键,MyISAM不支持。
5.从MySQL5.5.5以后,InnoDB是默认引擎。
6.InnoDB不支持FULLTEXT类型的索引。
7.InnoDB中不保存表的行数,如select count() from table时,InnoDB需要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count()语句包含where条件时MyISAM也需要扫描整个表。
8.对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引。
9.DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的 删除,效率非常慢。MyISAM则会重建表。
10.InnoDB支持行锁(某些情况下还是锁整表,如 update table set a=1 where user like ‘%lee%’。
2. MySQL存储引擎MyISAM与InnoDB如何选择
MySQL有多种存储引擎,每种存储引擎有各自的优缺点,可以择优选择使用:MyISAM、InnoDB、MERGE、MEMORY(HEAP)、BDB(BerkeleyDB)、EXAMPLE、FEDERATED、ARCHIVE、CSV、BLACKHOLE。
虽然MySQL里的存储引擎不只是MyISAM与InnoDB这两个,但常用的就是两个。
关于MySQL数据库提供的两种存储引擎,MyISAM与InnoDB选择使用:
- 1.INNODB会支持一些关系数据库的高级功能,如事务功能和行级锁,MyISAM不支持。
- 2.MyISAM的性能更优,占用的存储空间少,所以,选择何种存储引擎,视具体应用而定。
如果你的应用程序一定要使用事务,毫无疑问你要选择INNODB引擎。但要注意,INNODB的行级锁是有条件的。在where条件没有使用主键时,照样会锁全表。比如DELETE FROM mytable这样的删除语句。
如果你的应用程序对查询性能要求较高,就要使用MyISAM了。MyISAM索引和数据是分开的,而且其索引是压缩的,可以更好地利用内存。所以它的查询性能明显优于INNODB。压缩后的索引也能节约一些磁盘空间。MyISAM拥有全文索引的功能,这可以极大地优化LIKE查询的效率。
有人说MyISAM只能用于小型应用,其实这只是一种偏见。如果数据量比较大,这是需要通过升级架构来解决,比如分表分库,而不是单纯地依赖存储引擎。
现在一般都是选用innodb了,主要是MyISAM的全表锁,读写串行问题,并发效率锁表,效率低,MyISAM对于读写密集型应用一般是不会去选用的。
MEMORY存储引擎MEMORY是MySQL中一类特殊的存储引擎。它使用存储在内存中的内容来创建表,而且数据全部放在内存中。这些特性与前面的两个很不同。
每个基于MEMORY存储引擎的表实际对应一个磁盘文件。该文件的文件名与表名相同,类型为frm类型。该文件中只存储表的结构。而其数据文件,都是存储在内存中,这样有利于数据的快速处理,提高整个表的效率。值得注意的是,服务器需要有足够的内存来维持MEMORY存储引擎的表的使用。如果不需要了,可以释放内存,甚至删除不需要的表。MEMORY默认使用哈希索引。速度比使用B型树索引快。当然如果你想用B型树索引,可以在创建索引时指定。
注意,MEMORY用到的很少,因为它是把数据存到内存中,如果内存出现异常就会影响数据。如果重启或者关机,所有数据都会消失。因此,基于MEMORY的表的生命周期很短,一般是一次性的。
3. MySQL的MyISAM与InnoDB两种存储引擎在,事务、锁级别,各自的适用场景?
事务处理上方面
- MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
- InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
锁级别
- MyISAM:只支持表级锁,用户在操作MyISAM表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
- InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
关于存储引擎MyISAM和InnoDB的其他参考资料如下:
6.5 优化
1. 查询语句不同元素(where、jion、limit、group by、having等等)执行先后顺序?
- 1.查询中用到的关键词主要包含六个,并且他们的顺序依次为 select–from–where–group by–having–order by
其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序 与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据
- 2.from后面的表关联,是自右向左解析 而where条件的解析顺序是自下而上的。
也就是说,在写SQL语句的时候,尽量把数据量小的表放在最右边来进行关联(用小表去匹配大表),而把能筛选出小量数据的条件放在where语句的最左边 (用小表去匹配大表)
2. 使用explain优化sql和索引?
对于复杂、效率低的sql语句,我们通常是使用explain sql 来分析sql语句,这个语句可以打印出,语句的执行。这样方便我们分析,进行优化
table:显示这一行的数据是关于哪张表的
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL
all:full table scan ;MySQL将遍历全表以找到匹配的行;
index: index scan; index 和 all的区别在于index类型只遍历索引;
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值的行,常见与between ,等查询;
ref:非唯一性索引扫描,返回匹配某个单独值的所有行,常见于使用非唯一索引即唯一索引的非唯一前缀进行查找;
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或者唯一索引扫描;
const,system:当MySQL对某查询某部分进行优化,并转为一个常量时,使用这些访问类型。如果将主键置于where列表中,MySQL就能将该查询转化为一个常量。
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MySQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MySQL忽略索引
key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows:MySQL认为必须检查的用来返回请求数据的行数
Extra:关于MySQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MySQL根本不能使用索引,结果是检索会很慢。
3. MySQL慢查询怎么解决?
- slow_query_log 慢查询开启状态。
- slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)。
- long_query_time 查询超过多少秒才记录。
6.6 数据库锁
1. mysql都有什么锁,死锁判定原理和具体场景,死锁怎么解决?
MySQL有三种锁的级别:页级、表级、行级。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
什么情况下会造成死锁?什么是死锁?
死锁: 是指两个或两个以上的进程在执行过程中。因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等竺的进程称为死锁进程。
表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序。
死锁的解决办法?
1.查出的线程杀死 kill
SELECT trx_MySQL_thread_id FROM information_schema.INNODB_TRX;2.设置锁的超时时间
Innodb 行锁的等待时间,单位秒。可在会话级别设置,RDS 实例该参数的默认值为 50(秒)。生产环境不推荐使用过大的 innodb_lock_wait_timeout参数值
该参数支持在会话级别修改,方便应用在会话级别单独设置某些特殊操作的行锁等待超时时间,如下:
set innodb_lock_wait_timeout=1000; —设置当前会话 Innodb 行锁等待超时时间,单位秒。3.指定获取锁的顺序
2. 有哪些锁(乐观锁悲观锁),select 时怎么加排它锁?
悲观锁(Pessimistic Lock):
悲观锁特点:先获取锁,再进行业务操作。
即“悲观”的认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作。通常所说的“一锁二查三更新”即指的是使用悲观锁。通常来讲在数据库上的悲观锁需要数据库本身提供支持,即通过常用的select … for update操作来实现悲观锁。当数据库执行select for update时会获取被select中的数据行的行锁,因此其他并发执行的select for update如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。
补充:
不同的数据库对select for update的实现和支持都是有所区别的,
- oracle支持select for update no wait,表示如果拿不到锁立刻报错,而不是等待,MySQL就没有no wait这个选项。
- MySQL还有个问题是select for update语句执行中所有扫描过的行都会被锁上,这一点很容易造成问题。因此如果在MySQL中用悲观锁务必要确定走了索引,而不是全表扫描。
乐观锁(Optimistic Lock):
1.乐观锁,也叫乐观并发控制,它假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,那么当前正在提交的事务会进行回滚。
2.\*乐观锁的特点先进行业务操作,不到万不得已不去拿锁。*即“乐观”的认为拿锁多半是会成功的,因此在进行完业务操作需要实际更新数据的最后一步再去拿一下锁就好。
乐观锁在数据库上的实现完全是逻辑的,不需要数据库提供特殊的支持。3.一般的做法是在需要锁的数据上增加一个版本号,或者时间戳,
实现方式举例如下:
乐观锁(给表加一个版本号字段) 这个并不是乐观锁的定义,给表加版本号,是数据库实现乐观锁的一种方式。
- SELECT data AS old_data, version AS old_version FROM …;
- 根据获取的数据进行业务操作,得到new_data和new_version
- UPDATE SET data = new_data, version = new_version WHERE version = old_version
if (updated row > 0) {
// 乐观锁获取成功,操作完成
} else {
// 乐观锁获取失败,回滚并重试
}
注意:
- 乐观锁在不发生取锁失败的情况下开销比悲观锁小,但是一旦发生失败回滚开销则比较大,因此适合用在取锁失败概率比较小的场景,可以提升系统并发性能
- 乐观锁还适用于一些比较特殊的场景,例如在业务操作过程中无法和数据库保持连接等悲观锁无法适用的地方。
总结:
悲观锁和乐观锁是数据库用来保证数据并发安全防止更新丢失的两种方法,例子在select … for update前加个事务就可以防止更新丢失。悲观锁和乐观锁大部分场景下差异不大,一些独特场景下有一些差别,一般我们可以从如下几个方面来判断。
- 响应速度: 如果需要非常高的响应速度,建议采用乐观锁方案,成功就执行,不成功就失败,不需要等待其他并发去释放锁。’
- 冲突频率: 如果冲突频率非常高,建议采用悲观锁,保证成功率,如果冲突频率大,乐观锁会需要多次重试才能成功,代价比较大。
- 重试代价: 如果重试代价大,建议采用悲观锁。
七. 操作系统
7.1 Linux
1. 文件管理
1. cat 命令:连接文件
描述:cat 命令用于连接文件并打印到标准输出设备上。
功能:
# 1.一次显示整个文件: cat filename # 2.从键盘创建一个文件: cat > filename # 3.将几个文件合并为一个文件: cat file1 file2 > file示例:
(1)把 log2012.log 的文件内容加上行号后输入 log2013.log 这个文件里
cat -n log2012.log log2013.log(2)把 log2012.log 和 log2013.log 的文件内容加上行号(空白行不加)之后将内容附加到 log.log 里
cat -b log2012.log log2013.log log.log(3)使用 here doc 生成新文件
cat >log.txt <Hello >World >PWD=$(pwd) >EOF ls -l log.txt cat log.txt Hello World PWD=/opt/soft/test (4)反向列示
tac log.txt PWD=/opt/soft/test World Hello
2. chmod 命令: 权限控制
Linux/Unix 的文件调用权限分为三级 : 文件拥有者、群组、其他。利用 chmod 可以控制文件如何被他人所调用。
用于改变 linux 系统文件或目录的访问权限。用它控制文件或目录的访问权限。该命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。可使用 ls -l test.txt 查找。
以文件 log2012.log 为例:
-rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log第一列共有 10 个位置,第一个字符指定了文件类型。在通常意义上,一个目录也是一个文件。如果第一个字符是横线,表示是一个非目录的文件。如果是 d,表示是一个目录。从第二个字符开始到第十个 9 个字符,3 个字符一组,分别表示了 3 组用户对文件或者目录的权限。权限字符用横线代表空许可,r 代表只读,w 代表写,x 代表可执行。
常用参数:
- -c 当发生改变时,报告处理信息
- -R 处理指定目录以及其子目录下所有文件
权限范围:
- u :目录或者文件的当前的用户
- g :目录或者文件的当前的群组
- o :除了目录或者文件的当前用户或群组之外的用户或者群组
- a :所有的用户及群组
权限代号:
- r :读权限,用数字4表示
- w :写权限,用数字2表示
- x :执行权限,用数字1表示
- - :删除权限,用数字0表示
- s :特殊权限
实例:
(1)增加文件 t.log 所有用户可执行权限
chmod a+x t.log(2)撤销原来所有的权限,然后使拥有者具有可读权限,并输出处理信息
chmod u=r t.log -c(3)给 file 的属主分配读、写、执行(7)的权限,给file的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限
chmod 751 t.log -c(或者:chmod u=rwx,g=rx,o=x t.log -c)(4)将 test 目录及其子目录所有文件添加可读权限
chmod u+r,g+r,o+r -R text/ -c3. chown 命令:更改拥有者权限
chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户 ID;组可以是组名或者组 ID;文件是以空格分开的要改变权限的文件列表,支持通配符。
- -c 显示更改的部分的信息
- -R 处理指定目录及子目录
实例:
(1)改变拥有者和群组 并显示改变信息
chown -c mail:mail log2012.log(2)改变文件群组
chown -c :mail t.log(3)改变文件夹及子文件目录属主及属组为 mail
chown -cR mail: test/4. cp 命令:复制文件
将源文件复制至目标文件,或将多个源文件复制至目标目录。
注意:命令行复制,如果目标文件已经存在会提示是否覆盖,而在 shell 脚本中,如果不加 -i 参数,则不会提示,而是直接覆盖!
- -i 提示
- -r 复制目录及目录内所有项目
- -a 复制的文件与原文件时间一样
实例:
(1)复制 a.txt 到 test 目录下,保持原文件时间,如果原文件存在提示是否覆盖。
cp -ai a.txt test(2)为 a.txt 建议一个链接(快捷方式)
cp -s a.txt link_a.txt5. find 命令:查找文件
用于在文件树中查找文件,并作出相应的处理。
命令格式:
find pathname -options [-print -exec -ok ...]命令参数:
- pathname: find命令所查找的目录路径。例如用.来表示当前目录,用/来表示系统根目录。
- -print: find命令将匹配的文件输出到标准输出。
- -exec: find命令对匹配的文件执行该参数所给出的shell命令。相应命令的形式为’command’ { } ;,注意{ }和\;之间的空格。
- -ok: 和-exec的作用相同,只不过以一种更为安全的模式来执行该参数所给出的shell命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。
命令选项:
- -name 按照文件名查找文件
- -perm 按文件权限查找文件
- -user 按文件属主查找文件
- -group 按照文件所属的组来查找文件。
- -type 查找某一类型的文件,诸如:
- b - 块设备文件
- d - 目录
- c - 字符设备文件
- l - 符号链接文件
- p - 管道文件
- f - 普通文件
实例:
(1)查找 48 小时内修改过的文件
find -atime -2(2)在当前目录查找 以 .log 结尾的文件。 . 代表当前目录
find ./ -name '*.log'(3)查找 /opt 目录下 权限为 777 的文件
find /opt -perm 777(4)查找大于 1K 的文件
find -size +1000c查找等于 1000 字符的文件
find -size 1000c -exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面find查找出来的文件名。
6. head 命令:显示文件开头
head 用来显示档案的开头至标准输出中,默认 head 命令打印其相应文件的开头 10 行。
常用参数:
-n<行数> 显示的行数(行数为复数表示从最后向前数)实例:
(1)显示 1.log 文件中前 20 行
head 1.log -n 20(2)显示 1.log 文件前 20 字节
head -c 20 log2014.log(3)显示 t.log最后 10 行
head -n -10 t.log7. less 命令:文件浏览
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
常用命令参数:
- -i 忽略搜索时的大小写
- -N 显示每行的行号
- -o <文件名> 将less 输出的内容在指定文件中保存起来
- -s 显示连续空行为一行
- /字符串:向下搜索“字符串”的功能
- ?字符串:向上搜索“字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- -x <数字> 将“tab”键显示为规定的数字空格
- b 向后翻一页
- d 向后翻半页
- h 显示帮助界面
- Q 退出less 命令
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一行
- 回车键 滚动一页
- [pagedown]: 向下翻动一页
- [pageup]: 向上翻动一页
实例:
(1)ps 查看进程信息并通过 less 分页显示
ps -aux | less -N(2)查看多个文件
less 1.log 2.log可以使用 n 查看下一个,使用 p 查看前一个。
8. ln 命令:文件同步链接
功能是为文件在另外一个位置建立一个同步的链接,当在不同目录需要该问题时,就不需要为每一个目录创建同样的文件,通过 ln 创建的链接(link)减少磁盘占用量。
链接分类:软件链接及硬链接
软链接:
1.软链接,以路径的形式存在。类似于Windows操作系统中的快捷方式
2.软链接可以 跨文件系统 ,硬链接不可以
3.软链接可以对一个不存在的文件名进行链接
4.软链接可以对目录进行链接
硬链接:
1.硬链接,以文件副本的形式存在。但不占用实际空间。
2.不允许给目录创建硬链接
3.硬链接只有在同一个文件系统中才能创建
需要注意:
第一:ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
第二:ln的链接又分软链接和硬链接两种,软链接就是ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
第三:ln指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
常用参数:
- -b 删除,覆盖以前建立的链接
- -s 软链接(符号链接)
- -v 显示详细处理过程
实例:
(1)给文件创建软链接,并显示操作信息
ln -sv source.log link.log(2)给文件创建硬链接,并显示操作信息
ln -v source.log link1.log(3)给目录创建软链接
ln -sv /opt/soft/test/test3 /opt/soft/test/test59. locate 命令:快速查找档案
locate 通过搜寻系统内建文档数据库达到快速找到档案,数据库由 updatedb 程序来更新,updatedb 是由 cron daemon 周期性调用的。默认情况下 locate 命令在搜寻数据库时比由整个由硬盘资料来搜寻资料来得快,但较差劲的是 locate 所找到的档案若是最近才建立或 刚更名的,可能会找不到,在内定值中,updatedb 每天会跑一次,可以由修改 crontab 来更新设定值 (etc/crontab)。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找
常用参数:
- -l num(要显示的行数)
- -f 将特定的档案系统排除在外,如将proc排除在外
- -r 使用正则运算式做为寻找条件
实例:
(1)查找和 pwd 相关的所有文件(文件名中包含 pwd)
locate pwd(2)搜索 etc 目录下所有以 sh 开头的文件
locate /etc/sh(3)查找 /var 目录下,以 reason 结尾的文件
locate -r '^/var.*reason$'(其中.表示一个字符,*表示任务多个;.*表示任意多个字符)10. more 命令:文件分页浏览
功能类似于 cat, more 会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 b 键就会往回(back)一页显示。
命令参数:
- +n 从笫 n 行开始显示
- -n 定义屏幕大小为n行
- +/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
- -c 从顶部清屏,然后显示
- -d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
- -l 忽略Ctrl+l(换页)字符
- -p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
- -s 把连续的多个空行显示为一行
- -u 把文件内容中的下画线去掉
常用操作命令:
- Enter 向下 n 行,需要定义。默认为 1 行
- Ctrl+F 向下滚动一屏
- 空格键 向下滚动一屏
- Ctrl+B 返回上一屏
- = 输出当前行的行号
- :f 输出文件名和当前行的行号
- V 调用vi编辑器
- !命令 调用Shell,并执行命令
- q 退出more
实例:
(1)显示文件中从第3行起的内容
more +3 text.txt(2)在所列出文件目录详细信息,借助管道使每次显示 5 行
ls -l | more -5按空格显示下 5 行。
11. mv 命令:文件移动
移动文件或修改文件名,根据第二参数类型(如目录,则移动文件;如为文件则重命令该文件)。
当第二个参数为目录时,第一个参数可以是多个以空格分隔的文件或目录,然后移动第一个参数指定的多个文件到第二个参数指定的目录中。
实例:
(1)将文件 test.log 重命名为 test1.txt
mv test.log test1.txt(2)将文件 log1.txt,log2.txt,log3.txt 移动到根的 test3 目录中
mv llog1.txt log2.txt log3.txt /test3(3)将文件 file1 改名为 file2,如果 file2 已经存在,则询问是否覆盖
mv -i log1.txt log2.txt(4)移动当前文件夹下的所有文件到上一级目录
mv * ../12. rm 命令:文件删除
删除一个目录中的一个或多个文件或目录,如果没有使用 -r 选项,则 rm 不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
rm [选项] 文件…实例:
(1)删除任何 .log 文件,删除前逐一询问确认:
rm -i *.log(2)删除 test 子目录及子目录中所有档案删除,并且不用一一确认:
rm -rf test(3)删除以 -f 开头的文件
rm -- -f*13. tail 命令:显示文件末尾
用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
常用参数:
- -f 循环读取(常用于查看递增的日志文件)
- -n<行数> 显示行数(从后向前)
(1)循环读取逐渐增加的文件内容
ping 127.0.0.1 > ping.log &后台运行:可使用 jobs -l 查看,也可使用 fg 将其移到前台运行。
tail -f ping.log(查看日志)
14. touch 命令:修改时间属性
Linux touch命令用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录。
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]参数说明:
- a 改变档案的读取时间记录。
- m 改变档案的修改时间记录。
- c 假如目的档案不存在,不会建立新的档案。与 –no-create 的效果一样。
- f 不使用,是为了与其他 unix 系统的相容性而保留。
- r 使用参考档的时间记录,与 –file 的效果一样。
- d 设定时间与日期,可以使用各种不同的格式。
- t 设定档案的时间记录,格式与 date 指令相同。
- –no-create 不会建立新档案。
- –help 列出指令格式。
- –version 列出版本讯息。
实例
使用指令”touch”修改文件”testfile”的时间属性为当前系统时间,输入如下命令:
$ touch testfile #修改文件的时间属性 首先,使用ls命令查看testfile文件的属性,如下所示:
$ ls -l testfile #查看文件的时间属性 #原来文件的修改时间为16:09
-rw-r--r-- 1 hdd hdd 55 2011-08-22 16:09 testfile 执行指令”touch”修改文件属性以后,并再次查看该文件的时间属性,如下所示:
$ touch testfile #修改文件时间属性为当前系统时间
$ ls -l testfile #查看文件的时间属性 #修改后文件的时间属性为当前系统时间
-rw-r--r-- 1 hdd hdd 55 2011-08-22 19:53 testfile 使用指令”touch”时,如果指定的文件不存在,则将创建一个新的空白文件。例如,在当前目录下,使用该指令创建一个空白文件”file”,输入如下命令:
$ touch file #创建一个名为“file”的新的空白文件 15. vim 命令:文本编辑器
Vim是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
打开文件并跳到第 10 行:vim +10 filename.txt 。
打开文件跳到第一个匹配的行:vim +/search-term filename.txt 。
以只读模式打开文件:vim -R /etc/passwd 。
基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。
简单的说,我们可以将这三个模式想成底下的图标来表示:
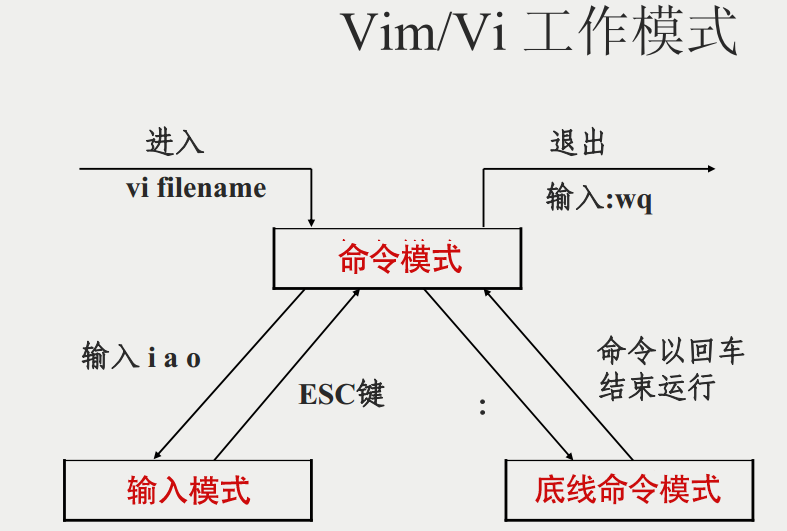
16. whereis 命令:搜索程序名
whereis 命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。whereis 及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而find则是遍历硬盘查找文件。
常用参数:
- -b 定位可执行文件。
- -m 定位帮助文件。
- -s 定位源代码文件。
- -u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件。
实例:
(1)查找 locate 程序相关文件
whereis locate(2)查找 locate 的源码文件
whereis -s locate(3)查找 lcoate 的帮助文件
whereis -m locate17. which 命令:查找文件
在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索:
- which 查看可执行文件的位置。
- whereis 查看文件的位置。
- locate 配合数据库查看文件位置。
- find 实际搜寻硬盘查询文件名称。
which 是在 PATH 就是指定的路径中,搜索某个系统命令的位置,并返回第一个搜索结果。使用 which 命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
常用参数:
-n 指定文件名长度,指定的长度必须大于或等于所有文件中最长的文件名。实例:
(1)查看 ls 命令是否存在,执行哪个
which ls(2)查看 which
which which(3)查看 cd
which cd(显示不存在,因为 cd 是内建命令,而 which 查找显示是 PATH 中的命令)查看当前 PATH 配置:
echo $PATH或使用 env 查看所有环境变量及对应值
2. 文档编辑
1. grep 命令:文本搜索
强大的文本搜索命令,grep(Global Regular Expression Print) 全局正则表达式搜索。
grep 的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
命令格式:
grep [option] pattern file|dir常用参数:
- -A n –after-context显示匹配字符后n行
- -B n –before-context显示匹配字符前n行
- -C n –context 显示匹配字符前后n行
- -c –count 计算符合样式的列数
- -i 忽略大小写
- -l 只列出文件内容符合指定的样式的文件名称
- -f 从文件中读取关键词
- -n 显示匹配内容的所在文件中行数
- -R 递归查找文件夹
grep 的规则表达式:
- ^ #锚定行的开始 如:’^grep’匹配所有以grep开头的行。
- $ #锚定行的结束 如:’grep’匹配所有以grep结尾的行。
- . #匹配一个非换行符的字符 如:’gr.p’匹配gr后接一个任意字符,然后是p。
- * #匹配零个或多个先前字符 如:’*grep’匹配所有一个或多个空格后紧跟grep的行。
- .* #一起用代表任意字符。
- [] #匹配一个指定范围内的字符,如’[Gg]rep’匹配Grep和grep。
- [^] #匹配一个不在指定范围内的字符,如:’[^A-FH-Z]rep’匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
- (..) #标记匹配字符,如’(love)‘,love被标记为1。
- < #锚定单词的开始,如:’<grep’匹配包含以grep开头的单词的行。
- > #锚定单词的结束,如’grep>‘匹配包含以grep结尾的单词的行。
- x{m} #重复字符x,m次,如:’0{5}‘匹配包含5个o的行。
- x{m,} #重复字符x,至少m次,如:’o{5,}‘匹配至少有5个o的行。
- x{m,n} #重复字符x,至少m次,不多于n次,如:’o{5,10}‘匹配5–10个o的行。
- \w #匹配文字和数字字符,也就是[A-Za-z0-9],如:’G\w*p’匹配以G后跟零个或多个文字或数字字符,然后是p。
- \W #\w的反置形式,匹配一个或多个非单词字符,如点号句号等。
- \b #单词锁定符,如: ‘\bgrep\b’只匹配grep。
实例:
(1)查找指定进程
ps -ef | grep svn(2)查找指定进程个数
ps -ef | grep svn -c(3)从文件中读取关键词
cat test1.txt | grep -f key.log(4)从文件夹中递归查找以grep开头的行,并只列出文件
grep -lR '^grep' /tmp(5)查找非x开关的行内容
grep '^[^x]' test.txt(6)显示包含 ed 或者 at 字符的内容行
grep -E 'ed|at' test.txt2. wc 命令:文件统计
wc(word count)功能为统计指定的文件中字节数、字数、行数,并将统计结果输出
命令格式:
wc [option] file..命令参数:
- -c 统计字节数
- -l 统计行数
- -m 统计字符数
- -w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
实例:
(1)查找文件的 行数 单词数 字节数 文件名
wc text.txt结果:
7 8 70 test.txt(2)统计输出结果的行数
cat test.txt | wc -l3. 磁盘管理
1. cd 命令:切换目录
cd(changeDirectory) 命令语法:
cd [目录名]说明:切换当前目录至 dirName。
实例:
(1)进入要目录
cd /(2)进入 “home” 目录
cd ~(3)进入上一次工作路径
cd -(4)把上个命令的参数作为cd参数使用。
cd !$2. df 命令:显示磁盘空间
显示磁盘空间使用情况。获取硬盘被占用了多少空间,目前还剩下多少空间等信息,如果没有文件名被指定,则所有当前被挂载的文件系统的可用空间将被显示。默认情况下,磁盘空间将以 1KB 为单位进行显示,除非环境变量 POSIXLY_CORRECT 被指定,那样将以512字节为单位进行显示:
- -a 全部文件系统列表
- -h 以方便阅读的方式显示信息
- -i 显示inode信息
- -k 区块为1024字节
- -l 只显示本地磁盘
- -T 列出文件系统类型
实例:
(1)显示磁盘使用情况
df -l(2)以易读方式列出所有文件系统及其类型
df -haT3. du 命令:查看文件使用空间
du 命令也是查看使用空间的,但是与 df 命令不同的是 Linux du 命令是对文件和目录磁盘使用的空间的查看:
命令格式:
du [选项] [文件]常用参数:
- -a 显示目录中所有文件大小
- -k 以KB为单位显示文件大小
- -m 以MB为单位显示文件大小
- -g 以GB为单位显示文件大小
- -h 以易读方式显示文件大小
- -s 仅显示总计
- -c或–total 除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
实例:
(1)以易读方式显示文件夹内及子文件夹大小
du -h scf/(2)以易读方式显示文件夹内所有文件大小
du -ah scf/(3)显示几个文件或目录各自占用磁盘空间的大小,还统计它们的总和
du -hc test/ scf/(4)输出当前目录下各个子目录所使用的空间
du -hc --max-depth=1 scf/4. ls命令:查看文件夹文件
就是 list 的缩写,通过 ls 命令不仅可以查看 linux 文件夹包含的文件,而且可以查看文件权限(包括目录、文件夹、文件权限)查看目录信息等等。
常用参数搭配:
- ls -a 列出目录所有文件,包含以.开始的隐藏文件
- ls -A 列出除.及..的其它文件
- ls -r 反序排列
- ls -t 以文件修改时间排序
- ls -S 以文件大小排序
- ls -h 以易读大小显示
- ls -l 除了文件名之外,还将文件的权限、所有者、文件大小等信息详细列出来
实例:
(1) 按易读方式按时间反序排序,并显示文件详细信息
ls -lhrt(2) 按大小反序显示文件详细信息
ls -lrS(3)列出当前目录中所有以”t”开头的目录的详细内容
ls -l t*(4) 列出文件绝对路径(不包含隐藏文件)
ls | sed "s:^:`pwd`/:"(5) 列出文件绝对路径(包含隐藏文件)
find $pwd -maxdepth 1 | xargs ls -ld5. mkdir 命令:创建文件夹
mkdir 命令用于创建文件夹。
可用选项:
- -m: 对新建目录设置存取权限,也可以用 chmod 命令设置;
- -p: 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不在的目录,即一次可以建立多个目录。
实例:
(1)当前工作目录下创建名为 t的文件夹
mkdir t(2)在 tmp 目录下创建路径为 test/t1/t 的目录,若不存在,则创建:
mkdir -p /tmp/test/t1/t6. pwd 命令:查看当前目录
pwd 命令用于查看当前工作目录路径。
实例:
(1)查看当前路径
pw(2)查看软链接的实际路径
pwd -P7. rmdir 命令:删除空目录
从一个目录中删除一个或多个子目录项,删除某目录时也必须具有对其父目录的写权限。
注意:不能删除非空目录
实例:
(1)当 parent 子目录被删除后使它也成为空目录的话,则顺便一并删除:
rmdir -p parent/child/child114. 网络通讯
1. ifconfig 命令:查看网络端口
ifconfig 用于查看和配置 Linux 系统的网络接口。
查看所有网络接口及其状态:ifconfig -a 。
使用 up 和 down 命令启动或停止某个接口:ifconfig eth0 up 和 ifconfig eth0 down 。
2. iptables 命令:开放端口
iptables ,是一个配置 Linux 内核防火墙的命令行工具。功能非常强大,对于我们开发来说,主要掌握如何开放端口即可。例如
把来源 IP 为 192.168.1.101 访问本机 80 端口的包直接拒绝:iptables -I INPUT -s 192.168.1.101 -p tcp –dport 80 -j REJECT 。
开启 80 端口,因为web对外都是这个端口
iptables -A INPUT -p tcp --dport 80 -j ACCEP另外,要注意使用 iptables save 命令,进行保存。否则,服务器重启后,配置的规则将丢失。
3. netstat 命令:查看网络连接状态
Linux netstat命令用于显示网络状态。
利用netstat指令可让你得知整个Linux系统的网络情况。
语法
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]参数说明:
- -a或–all 显示所有连线中的Socket。
- -A<网络类型>或–<网络类型> 列出该网络类型连线中的相关地址。
- -c或–continuous 持续列出网络状态。
- -C或–cache 显示路由器配置的快取信息。
- -e或–extend 显示网络其他相关信息。
- -F或–fib 显示FIB。
- -g或–groups 显示多重广播功能群组组员名单。
- -h或–help 在线帮助。
- -i或–interfaces 显示网络界面信息表单。
- -l或–listening 显示监控中的服务器的Socket。
- -M或–masquerade 显示伪装的网络连线。
- -n或–numeric 直接使用IP地址,而不通过域名服务器。
- -N或–netlink或–symbolic 显示网络硬件外围设备的符号连接名称。
- -o或–timers 显示计时器。
- -p或–programs 显示正在使用Socket的程序识别码和程序名称。
- -r或–route 显示Routing Table。
- -s或–statistice 显示网络工作信息统计表。
- -t或–tcp 显示TCP传输协议的连线状况。
- -u或–udp 显示UDP传输协议的连线状况。
- -v或–verbose 显示指令执行过程。
- -V或–version 显示版本信息。
- -w或–raw 显示RAW传输协议的连线状况。
- -x或–unix 此参数的效果和指定”-A unix”参数相同。
- –ip或–inet 此参数的效果和指定”-A inet”参数相同。
实例
1)如何查看系统都开启了哪些端口?
2)如何查看网络连接状况?

3)如何统计系统当前进程连接数?
输入命令 netstat -an | grep ESTABLISHED | wc -l 。
输出结果 177 。一共有 177 连接数。
4)用 netstat 命令配合其他命令,按照源 IP 统计所有到 80 端口的 ESTABLISHED 状态链接的个数?
严格来说,这个题目考验的是对 awk 的使用。
首先,使用 netstat -an|grep ESTABLISHED 命令。结果如下:
4. ping 命令:检测主机网络连接
Linux ping命令用于检测主机。
执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。
指定接收包的次数
ping -c 2 百度一下,你就知道5.telnet 命令:远端登陆
Linux telnet命令用于远端登入。
执行telnet指令开启终端机阶段作业,并登入远端主机。
语法
telnet [-8acdEfFKLrx][-b<主机别名>][-e<脱离字符>][-k<域名>][-l<用户名称>][-n<记录文件>][-S<服务类型>][-X<认证形态>][主机名称或IP地址<通信端口>]参数说明:
-8 允许使用8位字符资料,包括输入与输出。
-a 尝试自动登入远端系统。
-b<主机别名> 使用别名指定远端主机名称。
-c 不读取用户专属目录里的.telnetrc文件。
-d 启动排错模式。
-e<脱离字符> 设置脱离字符。
-E 滤除脱离字符。
-f 此参数的效果和指定"-F"参数相同。
-F 使用Kerberos V5认证时,加上此参数可把本地主机的认证数据上传到远端主机。
-k<域名> 使用Kerberos认证时,加上此参数让远端主机采用指定的领域名,而非该主机的域名。
-K 不自动登入远端主机。
-l<用户名称> 指定要登入远端主机的用户名称。
-L 允许输出8位字符资料。
-n<记录文件> 指定文件记录相关信息。
-r 使用类似rlogin指令的用户界面。
-S<服务类型> 设置telnet连线所需的IP TOS信息。
-x 假设主机有支持数据加密的功能,就使用它。
-X<认证形态> 关闭指定的认证形态。实例
登录远程主机
# 登录IP为 192.168.0.5 的远程主机
telnet 192.168.0.5 5. 系统管理
1. date 命令:显示系统日期
显示或设定系统的日期与时间。
命令参数:
- -d<字符串> 显示字符串所指的日期与时间。字符串前后必须加上双引号。
- -s<字符串> 根据字符串来设置日期与时间。字符串前后必须加上双引号。
-u 显示GMT。
%H 小时(00-23)
%I 小时(00-12)
%M 分钟(以00-59来表示)
%s 总秒数。起算时间为1970-01-01 00:00:00 UTC。
%S 秒(以本地的惯用法来表示)
%a 星期的缩写。
%A 星期的完整名称。
%d 日期(以01-31来表示)。
%D 日期(含年月日)。
%m 月份(以01-12来表示)。
%y 年份(以00-99来表示)。
%Y 年份(以四位数来表示)。
实例:
(1)显示下一天
date +%Y%m%d --date="+1 day" //显示下一天的日期(2)-d参数使用
date -d "nov 22" 今年的 11 月 22 日是星期三
date -d '2 weeks' 2周后的日期
date -d 'next monday' (下周一的日期)
date -d next-day +%Y%m%d(明天的日期)或者:date -d tomorrow +%Y%m%d
date -d last-day +%Y%m%d(昨天的日期) 或者:date -d yesterday +%Y%m%d
date -d last-month +%Y%m(上个月是几月)
date -d next-month +%Y%m(下个月是几月)2. free 命令:显示内存使用情况
显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
命令参数:
- -b 以Byte显示内存使用情况
- -k 以kb为单位显示内存使用情况
- -m 以mb为单位显示内存使用情况
- -g 以gb为单位显示内存使用情况
- -s<间隔秒数> 持续显示内存
- -t 显示内存使用总合
实例:
(1)显示内存使用情况
free
free -k
free -m(2)以总和的形式显示内存的使用信息
free -t(3)周期性查询内存使用情况
free -s 103. kill 命令:杀掉指定进程
发送指定的信号到相应进程。不指定型号将发送SIGTERM(15)终止指定进程。如果任无法终止该程序可用”-KILL” 参数,其发送的信号为SIGKILL(9) ,将强制结束进程,使用ps命令或者jobs 命令可以查看进程号。root用户将影响用户的进程,非root用户只能影响自己的进程。
常用参数:
- -l 信号,若果不加信号的编号参数,则使用“-l”参数会列出全部的信号名称
- -a 当处理当前进程时,不限制命令名和进程号的对应关系
- -p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
- -s 指定发送信号
- -u 指定用户
实例:
(1)先使用ps查找进程pro1,然后用kill杀掉
kill -9 $(ps -ef | grep pro1)4. ps 命令:查看运行进程(快照)
ps(process status),用来查看当前运行的进程状态,一次性查看,如果需要动态连续结果使用 top
linux上进程有5种状态:
- 运行(正在运行或在运行队列中等待)
- 中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
- 不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
- 僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
- 停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
ps 工具标识进程的5种状态码:
- D 不可中断 uninterruptible sleep (usually IO)
- R 运行 runnable (on run queue)
- S 中断 sleeping
- T 停止 traced or stopped
- Z 僵死 a defunct (”zombie”) process
命令参数:
- -A 显示所有进程
- a 显示所有进程
- -a 显示同一终端下所有进程
- c 显示进程真实名称
- e 显示环境变量
- f 显示进程间的关系
- r 显示当前终端运行的进程
- -aux 显示所有包含其它使用的进程
实例:
(1)显示当前所有进程环境变量及进程间关系
ps -ef(2)显示当前所有进程
ps -A(3)与grep联用查找某进程
ps -aux | grep apache(4)找出与 cron 与 syslog 这两个服务有关的 PID 号码
ps aux | grep '(cron|syslog)'5. rpm 命令:管理套件
Linux rpm 命令用于管理套件。
rpm(redhat package manager) 原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。
# 查看系统自带jdk
rpm -qa | grep jdk# 删除系统自带jdk
rpm -e --nodeps 查看jdk显示的数据# 安装jdk
rpm -ivh jdk-7u80-linux-x64.rpm6. top 命令:显示当前进程信息(动态)
显示当前系统正在执行的进程的相关信息,包括进程 ID、内存占用率、CPU 占用率等
常用参数:
- -c 显示完整的进程命令
- -s 保密模式
- -p <进程号> 指定进程显示
- -n <次数>循环显示次数
实例:
前五行是当前系统情况整体的统计信息区。
第一行,任务队列信息,同 uptime 命令的执行结果,具体参数说明情况如下:
14:06:23 — 当前系统时间
up 70 days, 16:44 — 系统已经运行了70天16小时44分钟(在这期间系统没有重启过的吆!)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行,Tasks — 任务(进程),具体信息说明如下:
系统现在共有206个进程,其中处于运行中的有1个,205个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行,cpu状态信息,具体属性说明如下:
- 5.9%us — 用户空间占用CPU的百分比。
- 3.4% sy — 内核空间占用CPU的百分比。
- 0.0% ni — 改变过优先级的进程占用CPU的百分比
- 90.4% id — 空闲CPU百分比
- 0.0% wa — IO等待占用CPU的百分比
- 0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
- 0.2% si — 软中断(Software Interrupts)占用CPU的百分比
备注:在这里CPU的使用比率和windows概念不同,需要理解linux系统用户空间和内核空间的相关知识!
第四行,内存状态,具体信息如下:
32949016k total — 物理内存总量(32GB)
14411180k used — 使用中的内存总量(14GB)
18537836k free — 空闲内存总量(18GB)
169884k buffers — 缓存的内存量 (169M)
第五行,swap交换分区信息,具体信息说明如下:
32764556k total — 交换区总量(32GB)
0k used — 使用的交换区总量(0K)
32764556k free — 空闲交换区总量(32GB)
3612636k cached — 缓冲的交换区总量(3.6GB)
第六行,空行。
第七行以下:各进程(任务)的状态监控,项目列信息说明如下:
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
7. top 交互命令:
- h 显示top交互命令帮助信息
- c 切换显示命令名称和完整命令行
- m 以内存使用率排序
- P 根据CPU使用百分比大小进行排序
- T 根据时间/累计时间进行排序
- W 将当前设置写入~/.toprc文件中
- o或者O 改变显示项目的顺序
8. yum 命令:软件包管理器
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载、安装。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
1.列出所有可更新的软件清单命令:yum check-update
2.更新所有软件命令:yum update
3.仅安装指定的软件命令:yum install
4.仅更新指定的软件命令:yum update
5.列出所有可安裝的软件清单命令:yum list
6.删除软件包命令:yum remove
7.查找软件包 命令:yum search
8.清除缓存命令:
yum clean packages: 清除缓存目录下的软件包
yum clean headers: 清除缓存目录下的 headers
yum clean oldheaders: 清除缓存目录下旧的 headers
yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软件包及旧的headers
实例
安装 pam-devel
[root@www ~]# yum install pam-devel6. 备份压缩
1. bzip2 命令:bz2文件压缩解压
创建 *.bz2 压缩文件:bzip2 test.txt 。
解压 *.bz2 文件:bzip2 -d test.txt.bz2 。2. gzip 命令:gz文件压缩解压
创建一个 *.gz 的压缩文件:gzip test.txt 。
解压 *.gz 文件:gzip -d test.txt.gz 。
显示压缩的比率:gzip -l *.gz 。3. tar 命令:文件打包
用来压缩和解压文件。tar 本身不具有压缩功能,只具有打包功能,有关压缩及解压是调用其它的功能来完成。
弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件
常用参数:
- -c 建立新的压缩文件
- -f 指定压缩文件
- -r 添加文件到已经压缩文件包中
- -u 添加改了和现有的文件到压缩包中
- -x 从压缩包中抽取文件
- -t 显示压缩文件中的内容
- -z 支持gzip压缩
- -j 支持bzip2压缩
- -Z 支持compress解压文件
- -v 显示操作过程
有关 gzip 及 bzip2 压缩:
gzip 实例:压缩 gzip fileName .tar.gz 和.tgz 解压:gunzip filename.gz 或 gzip -d filename.gz
对应:tar zcvf filename.tar.gz tar zxvf filename.tar.gz
bz2实例:压缩 bzip2 -z filename .tar.bz2 解压:bunzip filename.bz2或bzip -d filename.bz2
对应:tar jcvf filename.tar.gz 解压:tar jxvf filename.tar.bz2
实例:
(1)将文件全部打包成 tar 包
tar -cvf log.tar 1.log,2.log 或tar -cvf log.*(2)将 /etc 下的所有文件及目录打包到指定目录,并使用 gz 压缩
tar -zcvf /tmp/etc.tar.gz /etc(3)查看刚打包的文件内容(一定加z,因为是使用 gzip 压缩的)
tar -ztvf /tmp/etc.tar.gz(4)要压缩打包 /home, /etc ,但不要 /home/dmtsai
tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc4. unzip 命令
解压 *.zip 文件:unzip test.zip 。
查看 *.zip 文件的内容:unzip -l jasper.zip7.2 操作系统理论
1. 概述
基本特征
1. 并发
并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。
并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。
操作系统通过引入进程和线程,使得程序能够并发运行。
2. 共享
共享是指系统中的资源可以被多个并发进程共同使用。
有两种共享方式:互斥共享和同时共享。
互斥共享的资源称为临界资源,例如打印机等,在同一时间只允许一个进程访问,需要用同步机制来实现对临界资源的访问。
3. 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
主要有两种虚拟技术:时分复用技术和空分复用技术。
多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占有处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
4. 异步
异步指进程不是一次性执行完毕,而是走走停停,以不可知的速度向前推进。
基本功能
1. 进程管理
进程控制、进程同步、进程通信、死锁处理、处理机调度等。
2. 内存管理
内存分配、地址映射、内存保护与共享、虚拟内存等。
3. 文件管理
文件存储空间的管理、目录管理、文件读写管理和保护等。
4. 设备管理
完成用户的 I/O 请求,方便用户使用各种设备,并提高设备的利用率。
主要包括缓冲管理、设备分配、设备处理、虛拟设备等。
系统调用
如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。

Linux 的系统调用主要有以下这些:
| Task | Commands |
|---|---|
| 进程控制 | fork(); exit(); wait(); |
| 进程通信 | pipe(); shmget(); mmap(); |
| 文件操作 | open(); read(); write(); |
| 设备操作 | ioctl(); read(); write(); |
| 信息维护 | getpid(); alarm(); sleep(); |
| 安全 | chmod(); umask(); chown(); |
大内核和微内核
1. 大内核
大内核是将操作系统功能作为一个紧密结合的整体放到内核。
由于各模块共享信息,因此有很高的性能。
2. 微内核
由于操作系统不断复杂,因此将一部分操作系统功能移出内核,从而降低内核的复杂性。移出的部分根据分层的原则划分成若干服务,相互独立。
在微内核结构下,操作系统被划分成小的、定义良好的模块,只有微内核这一个模块运行在内核态,其余模块运行在用户态。
因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。

中断分类
1. 外中断
由 CPU 执行指令以外的事件引起,如 I/O 完成中断,表示设备输入/输出处理已经完成,处理器能够发送下一个输入/输出请求。此外还有时钟中断、控制台中断等。
2. 异常
由 CPU 执行指令的内部事件引起,如非法操作码、地址越界、算术溢出等。
3. 陷入
在用户程序中使用系统调用。
2. 进程管理
进程与线程
1. 进程
进程是资源分配的基本单位。
进程控制块 (Process Control Block, PCB) 描述进程的基本信息和运行状态,所谓的创建进程和撤销进程,都是指对 PCB 的操作。
下图显示了 4 个程序创建了 4 个进程,这 4 个进程可以并发地执行。

*2. *线程
线程是独立调度的基本单位。
一个进程中可以有多个线程,它们共享进程资源。
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。

3. 区别
Ⅰ 拥有资源
进程是资源分配的基本单位,但是线程不拥有资源,线程可以访问隶属进程的资源。
Ⅱ 调度
线程是独立调度的基本单位,在同一进程中,线程的切换不会引起进程切换,从一个进程中的线程切换到另一个进程中的线程时,会引起进程切换。
Ⅲ 系统开销
由于创建或撤销进程时,系统都要为之分配或回收资源,如内存空间、I/O 设备等,所付出的开销远大于创建或撤销线程时的开销。类似地,在进行进程切换时,涉及当前执行进程 CPU 环境的保存及新调度进程 CPU 环境的设置,而线程切换时只需保存和设置少量寄存器内容,开销很小。
Ⅳ 通信方面
线程间可以通过直接读写同一进程中的数据进行通信,但是进程通信需要借助 IPC。
进程状态的切换

- 就绪状态(ready):等待被调度
- 运行状态(running)
- 阻塞状态(waiting):等待资源
应该注意以下内容:
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
进程调度算法
不同环境的调度算法目标不同,因此需要针对不同环境来讨论调度算法。
1. 批处理系统
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
1.1 先来先服务 first-come first-serverd(FCFS)
按照请求的顺序进行调度。
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
1.2 短作业优先 shortest job first(SJF)
按估计运行时间最短的顺序进行调度。
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
1.3 最短剩余时间优先 shortest remaining time next(SRTN)
按估计剩余时间最短的顺序进行调度。
2. 交互式系统
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
2.1 时间片轮转
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
时间片轮转算法的效率和时间片的大小有很大关系:
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
- 而如果时间片过长,那么实时性就不能得到保证。

2.2 优先级调度
为每个进程分配一个优先级,按优先级进行调度。
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
2.3 多级反馈队列
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
多级队列是为这种需要连续执行多个时间片的进程考虑,它设置了多个队列,每个队列时间片大小都不同,例如 1,2,4,8,..。进程在第一个队列没执行完,就会被移到下一个队列。这种方式下,之前的进程只需要交换 7 次。
每个队列优先权也不同,最上面的优先权最高。因此只有上一个队列没有进程在排队,才能调度当前队列上的进程。
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。

3. 实时系统
实时系统要求一个请求在一个确定时间内得到响应。
分为硬实时和软实时,前者必须满足绝对的截止时间,后者可以容忍一定的超时。
进程同步
1. 临界区
对临界资源进行访问的那段代码称为临界区。
为了互斥访问临界资源,每个进程在进入临界区之前,需要先进行检查。
// entry section
// critical section;
// exit section2. 同步与互斥
- 同步:多个进程按一定顺序执行;
- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
3. 信号量
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
- down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
- up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否者其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
- 进程同步:控制多个进程按一定顺序执行;
- 进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h>
int pipe(int fd[2]);它具有以下限制:
- 只支持半双工通信(单向交替传输);
- 只能在父子进程中使用。

2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h>
int mkfifo(const char *path, mode_t mode);
int mkfifoat(int fd, const char *path, mode_t mode);FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。

3. 消息队列
相比于 FIFO,消息队列具有以下优点:
- 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
- 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4. 信号量
它是一个计数器,用于为多个进程提供对共享数据对象的访问。
5. 共享存储
允许多个进程共享一个给定的存储区。因为数据不需要在进程之间复制,所以这是最快的一种 IPC。
需要使用信号量用来同步对共享存储的访问。
多个进程可以将同一个文件映射到它们的地址空间从而实现共享内存。另外 XSI 共享内存不是使用文件,而是使用使用内存的匿名段。
6. 套接字
与其它通信机制不同的是,它可用于不同机器间的进程通信。
3. 死锁
必要条件

- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
处理方法
主要有以下四种方法:
- 鸵鸟策略
- 死锁检测与死锁恢复
- 死锁预防
- 死锁避免
鸵鸟策略
把头埋在沙子里,假装根本没发生问题。
因为解决死锁问题的代价很高,因此鸵鸟策略这种不采取任务措施的方案会获得更高的性能。
当发生死锁时不会对用户造成多大影响,或发生死锁的概率很低,可以采用鸵鸟策略。
大多数操作系统,包括 Unix,Linux 和 Windows,处理死锁问题的办法仅仅是忽略它。
死锁检测与死锁恢复
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
1. 每种类型一个资源的死锁检测

上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
图 a 可以抽取出环,如图 b,它满足了环路等待条件,因此会发生死锁。
每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
2. 每种类型多个资源的死锁检测

上图中,有三个进程四个资源,每个数据代表的含义如下:
- E 向量:资源总量
- A 向量:资源剩余量
- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
- R 矩阵:每个进程请求的资源数量
进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
算法总结如下:
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
- 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
- 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
- 如果没有这样一个进程,算法终止。
3. 死锁恢复
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
死锁预防
在程序运行之前预防发生死锁。
1. 破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。
2. 破坏占有和等待条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。
3. 破坏不可抢占条件
4. 破坏环路等待
给资源统一编号,进程只能按编号顺序来请求资源。
死锁避免
在程序运行时避免发生死锁。
1. 安全状态
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
定义:如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。
安全状态的检测与死锁的检测类似,因为安全状态必须要求不能发生死锁。下面的银行家算法与死锁检测算法非常类似,可以结合着做参考对比。
2. 单个资源的银行家算法
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。

上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
3. 多个资源的银行家算法

上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
检查一个状态是否安全的算法如下:
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
如果一个状态不是安全的,需要拒绝进入这个状态。
4. 内存管理
虚拟内存
虚拟内存的目的是为了让物理内存扩充成更大的逻辑内存,从而让程序获得更多的可用内存。
为了更好的管理内存,操作系统将内存抽象成地址空间。每个程序拥有自己的地址空间,这个地址空间被分割成多个块,每一块称为一页。这些页被映射到物理内存,但不需要映射到连续的物理内存,也不需要所有页都必须在物理内存中。当程序引用到不在物理内存中的页时,由硬件执行必要的映射,将缺失的部分装入物理内存并重新执行失败的指令。
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。

分页系统地址映射
内存管理单元(MMU)管理着地址空间和物理内存的转换,其中的页表(Page table)存储着页(程序地址空间)和页框(物理内存空间)的映射表。
一个虚拟地址分成两个部分,一部分存储页面号,一部分存储偏移量。
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。

页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。

3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
- R=0,M=0
- R=0,M=1
- R=1,M=0
- R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 先进先出
FIFO, First In First Out
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
5. 第二次机会算法
FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。

6. 时钟
Clock
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。

分段
虚拟内存采用的是分页技术,也就是将地址空间划分成固定大小的页,每一页再与内存进行映射。
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。

分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。

段页式
程序的地址空间划分成多个拥有独立地址空间的段,每个段上的地址空间划分成大小相同的页。这样既拥有分段系统的共享和保护,又拥有分页系统的虚拟内存功能。
分页与分段的比较
- 对程序员的透明性:分页透明,但是分段需要程序员显示划分每个段。
- 地址空间的维度:分页是一维地址空间,分段是二维的。
- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
八. 计算机网络
8.1 TCP和UDP的区别
TCP面向连接(三次握手机制),通信前需要先建立连接;UDP面向无连接,通信前不需要建立连接;
TCP保障可靠传输(按序、无差错、不丢失、不重复);UDP不保障可靠传输,使用最大努力交付;
TCP面向字节流的传输,UDP面向数据报的传输。
8.2 TCP协议的三次握手(连接)和四次挥手(关闭)
1. 三次握手过程
形象理解:
客户机:【how are you ?】
服务器:【fine.And you?】
客户机:【Fine.】
 |
具体过程:(SYN, (SYN+ACK), ACK)
(1)第一次握手:建立连接时,客户端A发送SYN包(SYN=j)到服务器B,并进入SYN_SEND状态,等待服务器B确认。
(2)第二次握手:服务器B收到SYN包,必须确认客户A的SYN(ACK=j+1),同时自己也发送一个SYN包(SYN=k),即SYN+ACK包,此时服务器B进入SYN_RECV状态。
(3)第三次握手:客户端A收到服务器B的SYN+ACK包,向服务器B发送确认包ACK(ACK=k+1),此包发送完毕,客户端A和服务器B进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据。
确认号:其数值等于发送方的发送序号 +1(即接收方期望接收的下一个序列号)。
2.**四次挥手过程**
 |
由于TCP连接是全双工的,一个TCP连接存在双向的读写通道,因此每个方向都必须单独进行关闭。TCP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
简单说来是 “先关读,后关写”,一共需要四个阶段。以客户机发起关闭连接为例:
1.服务器读通道关闭
2.客户机写通道关闭
3.客户机读通道关闭
4.服务器写通道关闭
关闭行为是在发起方数据发送完毕之后,给对方发出一个FIN(finish)数据段。直到接收到对方发送的FIN,且对方收到了接收确认ACK之后,双方的数据通信完全结束,过程中每次接收都需要返回确认数据段ACK。
详细过程:
第一阶段 客户机发送完数据之后,向服务器发送一个FIN数据段,序列号为i;
1.服务器收到FIN(i)后,返回确认段ACK,序列号为i+1,关闭服务器读通道;
2.客户机收到ACK(i+1)后,关闭客户机写通道;
(此时,客户机仍能通过读通道读取服务器的数据,服务器仍能通过写通道写数据)
第二阶段 服务器发送完数据之后,向客户机发送一个FIN数据段,序列号为j;
3.客户机收到FIN(j)后,返回确认段ACK,序列号为j+1,关闭客户机读通道;
4.服务器收到ACK(j+1)后,关闭服务器写通道。
这是标准的TCP关闭两个阶段,服务器和客户机都可以发起关闭,完全对称。
FIN标识是通过发送最后一块数据时设置的,标准的例子中,服务器还在发送数据,所以要等到发送完的时候,设置FIN(此时可称为TCP连接处于半关闭状态,因为数据仍可从被动关闭一方向主动关闭方传送)。如果在服务器收到FIN(i)时,已经没有数据需要发送,可以在返回ACK(i+1)的时候就设置FIN(j)标识,这样就相当于可以合并第二步和第三步。
8.3 TCP协议的通信状态
 |
整个通信状态如图
说明:客户端和服务器均有6个状态。其中经常问到的两个状态是TIME_WAIT和CLOSE_WAIT.
从图上可以发现,
TIME_WAIT状态是客户端【发起主动关闭的一方】在四次挥手第二阶段完成时,进入的状态。
CLOSE_WAIT状态是服务端【收到被动关闭的一方】在四次挥手的第一阶段完成时,进入的状态。
TIME_WAIT状态将持续2个MSL(Max Segment Lifetime),在Windows下默认为4分钟,即240秒。TIME_WAIT状态下的socket不能被回收使用. 具体现象是对于一个处理大量短连接的服务器,如果是由服务器主动关闭客户端的连接,将导致服务器端存在大量的处于TIME_WAIT状态的socket, 甚至比处于Established状态下的socket多的多,严重影响服务器的处理能力,甚至耗尽可用的socket,停止服务。
为什么需要TIME_WAIT?【保证Server最后收到了ACK】

原因有二:
一、保证TCP协议的全双工连接能够可靠关闭
二、保证这次连接的重复数据段从网络中消失
先说第一点,如果Client直接CLOSED了,那么由于IP协议的不可靠性或者是其它网络原因,导致Server没有收到Client最后回复的ACK。那么Server就会在超时之后继续发送FIN,此时由于Client已经CLOSED了,就找不到与重发的FIN对应的连接,最后Server就会收到RST而不是ACK,Server就会以为是连接错误把问题报告给高层。这样的情况虽然不会造成数据丢失,但是却导致TCP协议不符合可靠连接的要求。所以,Client不是直接进入CLOSED,而是要保持TIME_WAIT,当再次收到FIN的时候,能够保证对方收到ACK,最后正确的关闭连接。
再说第二点,如果Client直接CLOSED,然后又再向Server发起一个新连接,我们不能保证这个新连接与刚关闭的连接的端口号是不同的。也就是说有可能新连接和老连接的端口号是相同的。一般来说不会发生什么问题,但是还是有特殊情况出现:假设新连接和已经关闭的老连接端口号是一样的,如果前一次连接的某些数据仍然滞留在网络中,这些延迟数据在建立新连接之后才到达Server,由于新连接和老连接的端口号是一样的,又因为TCP协议判断不同连接的依据是socket pair,于是,TCP协议就认为那个延迟的数据是属于新连接的,这样就和真正的新连接的数据包发生混淆了。所以TCP连接还要在TIME_WAIT状态等待2倍MSL,这样可以保证本次连接的所有数据都从网络中消失。
8.4 网络编程时的同步、异步、阻塞、非阻塞
同步/异步主要针对C端:
同步:
所谓同步,就是在c端发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做,等前一件做完了才能做下一件事。
例如普通B/S模式(同步):提交请求->等待服务器处理->处理完毕返回 这个期间客户端浏览器不能干任何事
异步:
异步的概念和同步相对。当c端一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
例如 ajax请求(异步): 请求通过事件触发->服务器处理(这是浏览器仍然可以作其他事情)->处理完毕
阻塞/非阻塞主要针对S端:
阻塞
阻塞调用是指调用结果返回之前,当前线程会被挂起(线程进入非可执行状态,在这个状态下,cpu不会给线程分配时间片,即线程暂停运行)。函数只有在得到结果之后才会返回。
有人也许会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 例如,我们在socket中调用recv函数,如果缓冲区中没有数据,这个函数就会一直等待,直到有数据才返回。而此时,当前线程还会继续处理各种各样的消息。
快递的例子:比如到你某个时候到A楼一层(假如是内核缓冲区)取快递,但是你不知道快递什么时候过来,你又不能干别的事,只能死等着。但你可以睡觉(进程处于休眠状态),因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。
非阻塞
非阻塞和阻塞的概念相对应,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
还是等快递的例子:如果用忙轮询的方法,每隔5分钟到A楼一层(内核缓冲区)去看快递来了没有。如果没来,立即返回。而快递来了,就放在A楼一层,等你去取。
对象的阻塞模式和阻塞函数调用
对象是否处于阻塞模式和函数是不是阻塞调用有很强的相关性,但是并不是一一对应的。阻塞对象上可以有非阻塞的调用方式,我们可以通过一定的API去轮询状 态,在适当的时候调用阻塞函数,就可以避免阻塞。而对于非阻塞对象,调用特殊的函数也可以进入阻塞调用。函数select就是这样的一个例子。
总结几句话就是:
同步/异步主要针对C端
\1. 同步,就是我客户端(c端调用者)调用一个功能,该功能没有结束前,我(c端调用者)死等结果。
\2. 异步,就是我(c端调用者)调用一个功能,不需要知道该功能结果,该功能有结果后通知我(c端调用者)即回调通知。
阻塞/非阻塞主要针对S端
\3. 阻塞, 就是调用我(s端被调用者,函数),我(s端被调用者,函数)没有接收完数据或者没有得到结果之前,我不会返回。
\4. 非阻塞, 就是调用我(s端被调用者,函数),我(s端被调用者,函数)立即返回,通过select通知调用者
8.5 进程间通信方式
1.**什么是进程间通信?**
由于不同的进程运行在各自不同的内存空间中,其中一个进程对于变量的修改另一方是无法感知的,因此,进程之间的消息传递不能通过变量或其他数据结构直接进行,只能通过进程间通信来完成.
进程间通信是指不同进程间进行数据共享和数据交换.
2.**进程通信的分类**
根据进程通信时信息量大小的不同,可以将进程通信划分为两大类型:
控制信息的通信(低级通信)和大批数据信息的通信(高级通信).
低级通信主要用于进程之间的同步,互斥,终止和挂起等等控制信息的传递.
高级通信主要用于进程间数据块数据的交换和共享,常见的高级通信有管道,消息队列,共享内存等.
进程通信的方式
1)管道【管道分为有名管道和无名管道】
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用.进程的亲缘关系一般指的是父子关系.管道一般用于两个不同进程之间的通信.当一个进程创建了一个管道,并调用fork创建自己的一个子进程后,父进程关闭读管道端,子进程关闭写管道端,这样提供了两个进程之间数据流动的一种方式.
2)信号量
信号量是一个计数器,可以用来控制多个线程对共享资源的访问.,它不是用于交换大批数据,而用于多线程之间的同步.它常作为一种锁机制,防止某进程在访问资源时其它进程也访问该资源.因此,主要作为进程间以及同一个进程内不同线程之间的同步手段.
3)信号
信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生.
4)消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符标识.消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等特点.消息队列是UNIX下不同进程之间可实现共享资源的一种机制,UNIX允许不同进程将格式化的数据流以消息队列形式发送给任意进程.对消息队列具有操作权限的进程都可以使用msget完成对消息队列的操作控制.通过使用消息类型,进程可以按任何顺序读信息,或为消息安排优先级顺序.
5)共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问.共享内存是最快的IPC(进程间通信)方式,它是针对其它进程间通信方式运行效率低而专门设计的.它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步与通信.
6)套接字(socket)
套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同进程及其间进程的通信.
3.**各种通信方式的优缺点**
无名管道简单方便.但局限于单向通信的工作方式.并且只能在创建它的进程及其子孙进程之间实现管道的共享:有名管道虽然可以提供给任意关系的进程使用.但是由于其长期存在于系统之中,使用不当容易出错.所以普通用户一般不建议使用。
消息队列可以不再局限于父子进程.而允许任意进程通过共享消息队列来实现进程间通信.并由系统调用函数来实现消息发送和接收之间的同步.从而使得用户在使用消息缓冲进行通信时不再需要考虑同步问题.使用方便,但是消息队列中信息的复制需要额外消耗CPU的时间.不适宜于信息量大或操作频繁的场合。
因此.对于不同的应用问题,要根据问题本身的情况来选择进程间的通信方式。
8.6 TCP的流量控制和拥塞控制
流量控制【点对点】
所谓的流量控制就是让发送方的发送速率不要太快,让接收方来得及接受。利用滑动窗口机制可以很方便的在TCP连接上实现对发送方的流量控制。
拥塞控制【网络资源】
在某段时间,若对网络中的某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变化,这种情况叫做拥塞。
所谓拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能承受现有的网络负荷。
流量控制往往指的是点对点通信量的控制,是个端到端的问题。流量控制所要做的就是控制发送端发送数据的速率,以便使接收端来得及接受。
拥塞控制的四种算法,即慢开始(Slow-start),拥塞避免(Congestion Avoidance)快重传(Fast Restrangsmit)和快回复(Fast Recovery)
九. 大数据算法
9.1 两个超大文件找共同出现的单词
1.题目描述
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
2.思考过程
(1)首先我们最常想到的方法是读取文件a,建立哈希表(为什么要建立hash表?因为方便后面的查找),然后再读取文件b,遍历文件b中每个url,对于每个遍历,我们都执行查找hash表的操作,若hash表中搜索到了,则说明两文件共有,存入一个集合。
(2)但上述方法有一个明显问题,加载一个文件的数据需要50亿*64bytes = 320G远远大于4G内存,何况我们还需要分配哈希表数据结构所使用的空间,所以不可能一次性把文件中所有数据构建一个整体的hash表。
(3)针对上述问题,我们分治算法的思想。
step1:遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,…,a999,每个小文件约300M),为什么是1000?主要根据内存大小和要分治的文件大小来计算,我们就大致可以把320G大小分为1000份,每份大约300M(当然,到底能不能分布尽量均匀,得看hash函数的设计)
step2:遍历文件b,采取和a相同的方式将url分别存储到1000个小文件(记为b0,b1,…,b999)(为什么要这样做? 文件a的hash映射和文件b的hash映射函数要保持一致,这样的话相同的url就会保存在对应的小文件中,比如,如果a中有一个url记录data1被hash到了a99文件中,那么如果b中也有相同url,则一定被hash到了b99中)
所以现在问题转换成了:找出1000对小文件中每一对相同的url(不对应的小文件不可能有相同的url)
step3:因为每个hash大约300M,所以我们再可以采用(1)中的想法
最后对两个新的url文件做hadoop计数,reduce的结果中count为2的即是重复项。
也可用其他方法。
9.2 海量数据求 TopN
问题描述
有1亿个浮点数,如果找出期中最大的10000个?
解题思路
最容易想到的方法是将数据全部排序,然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为O(nlogn),如快速排序。但是在32位的机器上,每个float类型占4个字节,1亿个浮点数就要占用400MB的存储空间,对于一些可用内存小于400M的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是8GB),该方法也并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
第二种方法为局部淘汰法,该方法与排序方法类似,用一个容器保存前10000个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小,即10000。
第三种方法是分治法,将1亿个数据分成100份,每份100万个数据,找到每份数据中最大的10000个,最后在剩下的100*10000个数据里面找出最大的10000个。如果100万数据选择足够理想,那么可以过滤掉1亿数据里面99%的数据。100万个数据里面查找最大的10000个数据的方法如下:用快速排序的方法,将数据分为2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于10000个,就在小的那堆里面快速排序一次,找第10000-n大的数字;递归以上过程,就可以找到第1w大的数。参考上面的找出第1w大数字,就可以类似的方法找到前10000大数字了。此种方法需要每次的内存空间为10^64=4MB,一共需要101次这样的比较。
第四种方法是Hash法。如果这1亿个数里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
第五种方法采用最小堆。首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至1亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有10000个数字。该算法的时间复杂度为O(nmlogm),空间复杂度是10000(常数)。
9.3 海量数据找出不重复的(整数)数据(分治+位图法)
题目描述
在 2.5 亿个整数中找出不重复的整数。注意:内存不足以容纳这 2.5 亿个整数。
解答思路
方法一:分治法
与前面的题目方法类似,先将 2.5 亿个数划分到多个小文件,用 HashSet/HashMap 找出每个小文件中不重复的整数,再合并每个子结果,即为最终结果。
方法二:位图法(bit-map)
位图,就是用一个或多个 bit 来标记某个元素对应的值,而键就是该元素。采用位作为单位来存储数据,可以大大节省存储空间。
位图通过使用位数组来表示某些元素是否存在。它可以用于快速查找,判重,排序等。不是很清楚?我先举个小例子。
假设我们要对 [0,7] 中的 5 个元素 (6, 4, 2, 1, 5) 进行排序,可以采用位图法。0~7 范围总共有 8 个数,只需要 8bit,即 1 个字节。首先将每个位都置 0:
0 0 0 0 0 0 0 0
然后遍历 5 个元素,首先遇到 6,那么将下标为 6 的位的 0 置为 1;接着遇到 4,把下标为 4 的位 的 0 置为 1:
0 0 0 0 1 0 1 0
依次遍历,结束后,位数组是这样的:
0 1 1 0 1 1 1 0
每个为 1 的位,它的下标都表示了一个数:
for i in range(8):
if bits[i] == 1:
print(i)
1
2
3
这样我们其实就已经实现了排序。
对于整数相关的算法的求解,位图法是一种非常实用的算法。假设 int 整数占用 4B,即 32bit,那么我们可以表示的整数的个数为 232。
那么对于这道题,我们用 2 个 bit 来表示各个数字的状态:
00 表示这个数字没出现过;
01 表示这个数字出现过一次(即为题目所找的不重复整数);
10 表示这个数字出现了多次。那么这 232 个整数,总共所需内存为
232*2b=1GB。因此,当可用内存超过 1GB 时,可以采用位图法。假设内存满足位图法需求,进行下面的操作:
遍历 2.5 亿个整数,查看位图中对应的位,如果是 00,则变为 01,如果是 01 则变为 10,如果是 10 则保持不变。遍历结束后,查看位图,把对应位是 01 的整数输出即可。
方法总结
判断数字是否重复的问题,位图法是一种非常高效的方法。
9.4 布隆过滤器
什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
实现原理
HashMap 的问题
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到 HashMap 的 Key,然后可以在 O(1) 的时间复杂度内返回结果,效率奇高。但是 HashMap 的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那 HashMap 占据的内存大小就变得很可观了。
还比如说你的数据集存储在远程服务器上,本地服务接受输入,而数据集非常大不可能一次性读进内存构建 HashMap 的时候,也会存在问题。
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:

如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:

Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
支持删除么
传统的布隆过滤器并不支持删除操作。但是名为 Counting Bloom filter 的变种可以用来测试元素计数个数是否绝对小于某个阈值,它支持元素删除。可以参考文章 Counting Bloom Filter 的原理和实现
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。

如何选择适合业务的 k 和 m 值呢,这里直接贴一个公式:

k 为哈希函数个数,m 为布隆过滤器长度,n 为插入的元素个数,p 为误报率。
至于如何推导这个公式,我在知乎发布的文章有涉及,感兴趣可以看看,不感兴趣的话记住上面这个公式就行了。
最佳实践
常见的适用常见有,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
另外,既然你使用布隆过滤器来加速查找和判断是否存在,那么性能很低的哈希函数不是个好选择,推荐 MurmurHash、Fnv 这些。
大Value拆分
Redis 因其支持 setbit 和 getbit 操作,且纯内存性能高等特点,因此天然就可以作为布隆过滤器来使用。但是布隆过滤器的不当使用极易产生大 Value,增加 Redis 阻塞风险,因此生成环境中建议对体积庞大的布隆过滤器进行拆分。
拆分的形式方法多种多样,但是本质是不要将 Hash(Key) 之后的请求分散在多个节点的多个小 bitmap 上,而是应该拆分成多个小 bitmap 之后,对一个 Key 的所有哈希函数都落在这一个小 bitmap 上
9.5 bit-map
Bit-map的基本思想
32位机器上,对于一个整型数,比如int a=1 在内存中占32bit位,这是为了方便计算机的运算。但是对于某些应用场景而言,这属于一种巨大的浪费,因为我们可以用对应的32bit位对应存储十进制的0-31个数,而这就是Bit-map的基本思想。Bit-map算法利用这种思想处理大量数据的排序、查询以及去重。Bitmap在用户群做交集和并集运算的时候也有极大的便利。
在此我用一个简单的例子来详细介绍BitMap算法的原理。
假设我们要对0-7内的5个元素(4,7,2,5,3)进行排序(这里假设元素没有重复)。我们可以使用BitMap算法达到排序目的。要表示8个数,我们需要8个byte。
1.首先我们开辟一个字节(8byte)的空间,将这些空间的所有的byte位都设置为0
2.然后便利这5个元素,第一个元素是4,因为下边从0开始,因此我们把第五个字节的值设置为1
3.然后再处理剩下的四个元素,最终8个字节的状态如下图
4.现在我们遍历一次bytes区域,把值为1的byte的位置输出(2,3,4,5,7),这样便达到了排序的目的
从上面的例子我们可以看出,BitMap算法的思想还是比较简单的,关键的问题是如何确定10进制的数到2进制的映射图
MAP映射:
假设需要排序或则查找的数的总数N=100000000,BitMap中1bit代表一个数字,1个int = 4Bytes = 4*8bit = 32 bit,那么N个数需要N/32 int空间。所以我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
a[0]—————————–> 0-31
a[1]——————————> 32-63
a[2]——————————-> 64-95
a[3]——————————–> 96-127
………………………………………………
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位:
1.求十进制数在对应数组a中的下标
十进制数0-31,对应在数组a[0]中,32-63对应在数组a[1]中,64-95对应在数组a[2]中………,使用数学归纳分析得出结论:对于一个十进制数n,其在数组a中的下标为:a[n/32]
2.求出十进制数在对应数a[i]中的下标
例如十进制数1在a[0]的下标为1,十进制数31在a[0]中下标为31,十进制数32在a[1]中下标为0。 在十进制0-31就对应0-31,而32-63则对应也是0-31,即给定一个数n可以通过模32求得在对应数组a[i]中的下标。
3.位移
对于一个十进制数n,对应在数组a[n/32][n%32]中,但数组a毕竟不是一个二维数组,我们通过移位操作实现置1
a[n/32] |= 1 << n % 32
移位操作:
a[n>>5] |= 1 << (n & 0x1F)
n & 0x1F 保留n的后五位 相当于 n % 32 求十进制数在数组a[i]中的下标。
9.6 字典树
Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。字典树(Trie)可以保存一些 字符串 -> 值 的对应关系。基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
Trie 的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关。Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题;
Trie 的缺点是空间消耗很高。
典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie树的基本性质:
(1)根节点不包含字符,除根节点意外每个节点只包含一个字符。
(2)从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
(3)每个节点的所有子节点包含的字符串不相同。
(4)如果字符的种数为n,则每个结点的出度为n,这也是空间换时间的体现,浪费了很多的空间。
(5)插入查找的复杂度为O(n),n为字符串长度。
基本思想(以字母树为例):
1、插入过程
对于一个单词,从根开始,沿着单词的各个字母所对应的树中的节点分支向下走,直到单词遍历完,将最后的节点标记为红色,表示该单词已插入Trie树。
2、查询过程
同样的,从根开始按照单词的字母顺序向下遍历trie树,一旦发现某个节点标记不存在或者单词遍历完成而最后的节点未标记为红色,则表示该单词不存在,若最后的节点标记为红色,表示该单词存在。
字典树的数据结构
一般可以按下面步骤构建:
利用串构建一个字典树,这个字典树保存了串的公共前缀信息,因此可以降低查询操作的复杂度。
下面以英文单词构建的字典树为例,这棵Trie树中每个结点包括26个孩子结点,因为总共有26个英文字母(假设单词都是小写字母组成)。
则可声明包含Trie树的结点信息的结构体:
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;其中next是一个指针数组,存放着指向各个孩子结点的指针。
其中next是一个指针数组,存放着指向各个孩子结点的指针。
如给出字符串”abc”,”ab”,”bd”,”dda”,根据该字符串序列构建一棵Trie树。则构建的树如下:
9.7 倒排索引
倒排索引是目前搜索引擎公司对搜索引擎最常用的存储方式,也是搜索引擎的核心内容,在搜索引擎的实际应用中,有时需要按照关键字的某些值查找记录,所以是按照关键字建立索引,这个索引就被称为倒排索引。
首先你要明确,索引这东西,一般是用于提高查询效率的。举个最简单的例子,已知有5个文本文件,需要我们去查某个单词位于哪个文本文件中,最直观的做法就是挨个加载每个文本文件中的单词到内存中,然后用for循环遍历一遍数组,直到找到这个单词。这种做法就是正向索引的思路。
正向索引的这种查询效率也不需要我多吐槽了。倒排索引的思路其实也并不难。再举一个例子,有两段文本
D1:Hello, conan!
D2:Hello, hattori!
第一步,找到所有的单词
Hello、conan、hattori
第二步,找到包含这些单词的文本位置
Hello(D1,D2)
conan(D1)
hattori(D2)
我们将单词作为Hash表的Key,将所在的文本位置作为Hash表的Value保存起来。
当我们要查询某个单词的所在位置时,只需要根据这张Hash表就可以迅速的找到目标文档。
结合之前的说的正向索引,不难发现。正向索引是通过文档去查找单词,反向索引则是通过单词去查找文档。
倒排索引的优点还包括在处理复杂的多关键字查询时,可在倒排表中先完成查询的并、交等逻辑运算,得到结果后再对记录进行存取,这样把对文档的查询转换为地址集合的运算,从而提高查找速度。
十. 数据结构和算法
10.1 数组
连续子数组的最大和
调整数组顺序使奇数位于偶数前面
10.2 链表
1. 链表删除
删除链表中的节点
核心代码:
class Solution:
def deleteNode(self, node):
node.val = node.next.val
node.next = node.next.next[python 垃圾回收机制
引用计数
Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用,『引用计数法』的原理是:每个对象维护一个
ob_ref字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_ref加1,每当该对象的引用失效时计数ob_ref减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。标记清除
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。

在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
奇偶链表
核心代码
class Solution:
def oddEvenList(self, head: ListNode) -> ListNode:
if not head:return head
odd = head
even_head = even = head.next
while odd.next and even.next:
odd.next = odd.next.next
even.next = even.next.next
odd,even = odd.next,even.next
odd.next = even_head
return head知识点:
2. 链表合并
1.2.1 合并两个有序链表
核心代码
3. 链表反转
1.3.1 K 个一组翻转链表
解题答案:
Python版
#官方题解:
class Solution:
# 翻转一个子链表,并且返回新的头与尾
def reverse(self, head: ListNode, tail: ListNode):
prev = tail.next
p = head
while prev != tail:
nex = p.next
p.next = prev
prev = p
p = nex
return tail, head
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
hair = ListNode(0)
hair.next = head
pre = hair
while head:
tail = pre
# 查看剩余部分长度是否大于等于 k
for i in range(k):
tail = tail.next
if not tail:
return hair.next
nex = tail.next
head, tail = self.reverse(head, tail)
# 把子链表重新接回原链表
pre.next = head
tail.next = nex
pre = tail
head = tail.next
return hair.next
#复杂度分析
时间复杂度:O(n),其中 n为链表的长度。head 指针会在O(N/K)
个结点上停留,每次停留需要进行一次 O(k)的翻转操作。
空间复杂度:O(1),我们只需要建立常数个变量。
#网友解法:
复杂度分析
时间复杂度:O(N)。
空间复杂度:O(1)。#时间最优解法
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
# 判断链表长度是否大于K
cur = head
for _ in range(k):
if not cur: return head
cur = cur.next
# 反转头部的长度为k的子链表
pre = head
itera = head.next
for _ in range(k-1):
next = itera.next
itera.next = pre
pre = itera
itera = next
# 反转链表的剩余部分
head.next = self.reverseKGroup(cur, k)
return pre 知识点
反转链表操作
4. 链表相交
1.4.1 相交链表
核心代码
--5. 链表旋转
1.5.1 旋转链表
核心代码
10.3 字符串
1. 字符串比较
比较字符串最小字母出现频次
比较版本号
核心代码:



