1.前言
该讲主要引导读者从全局去了解什么是数据分析?为什么做数据分析?怎么去做数据分析?答案就是:掌握数据,就是掌握规律。当你了解了市场数据,对它进行分析,就可以得到市场规律。当你掌握了产品自身的数据,对它进行分析,就可以了解产品的用户来源、用户画像等等。所以说数据是个全新的视角。数据分析如此重要,它不仅是新时代的“数据结构 + 算法”,也更是企业争夺人才的高地。 谈到数据分析,我们一般都会从3个方面入手:
数据采集 – 数据源,我们要用的原材料
数据挖掘 – 它可以说是最“高大上”的部分,也是整个商业价值所在。之所以要进行数据分析,就是要找到其中的规律,来指导我们的业务。因此数据挖掘的核心是挖掘数据的商业价值(所谓的商业智能BI)
数据的可视化 – 数据领域中的万金油,直观了解数据分析结构
数据分析的三驾马车的关系如下:
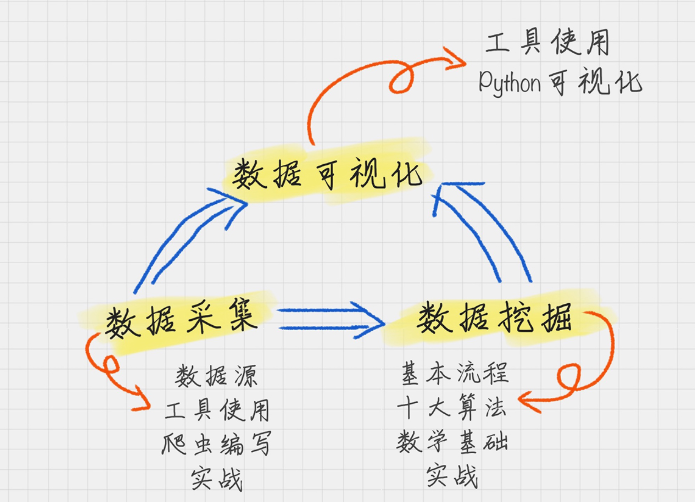
下面来大致认识下这三驾马车:
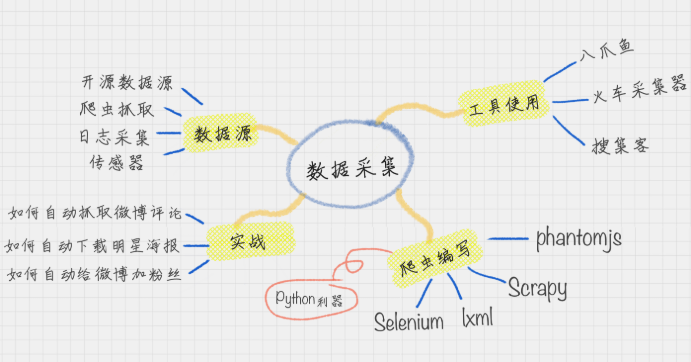
2.数据采集:
数据的采集,主要是和数据打交道,用工具对数据进行采集,常用的数据源,如何获取它们。在专栏里,后续会将介绍如何掌握“八爪鱼”这个自动抓取的神器,它可以帮你抓取 99% 的页面源。也会教读者如何编写 Python 爬虫。掌握 Python 爬虫的乐趣是无穷的。它不仅能让你获取微博上的热点评论,自动下载例如“王祖贤”的海报,还能自动给微博加粉丝,让你掌握自动化的快感。
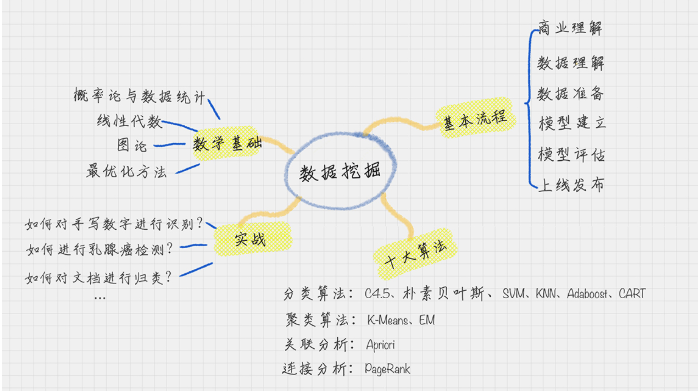
3.数据挖掘:
数据挖掘,它可以说是知识型的工程,相当于整个专栏中的“算法”部分。首先你要知道它的基本流程、十大算法、以及背后的数学基础。
掌握了数据挖掘,就好比手握水晶球一样,它会通过历史数据,告诉你未来会发生什么。当然它也会告诉你这件事发生的置信度是怎样的。
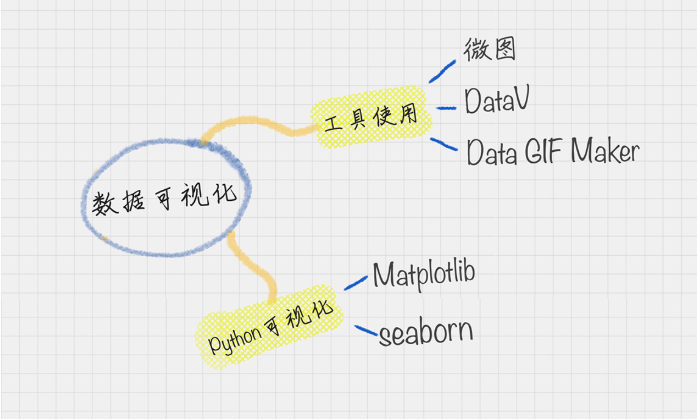
4.数据可视化
为什么说数据要可视化,因为数据往往是隐性的,尤其是当数据量大的时候很难感知,可视化可以帮我们很好地理解这些数据的结构,以及分析结果的呈现。这是一个非常重要的步骤,也是我们特别感兴趣的一个步骤。
数据可视化的两种方法:
Python :在 Python 对数据进行清洗、挖掘的过程中,很多的库可以使用,像 Matplotlib、Seaborn 等第三方库进行呈现。
第三方工具:如果你已经生成了 csv 格式文件,想要采用所见即所得的方式进行呈现,可以采用微图、DataV、Data GIF Maker 等第三方工具,它们可以很方便地对数据进行处理,还可以帮你制作呈现的效果。
数据分析包括数据采集、数据挖掘、数据可视化这三个部分。乍看你可能觉得东西很多,无从下手,或者感觉数据挖掘涉及好多算法,有点“高深莫测”,掌握起来是不是会吃力。其实这些都是不必要的烦恼。个人觉得只要内心笃定,认为自己一定能做成,学成,其他一切都是“纸老虎”哈。
再说下,陈博在文章中提到的如何来快速掌握数据分析,核心就是认知。我们只有把知识转化为自己的语言,它才真正变成了我们自己的东西。这个转换的过程就是认知升级的过程。
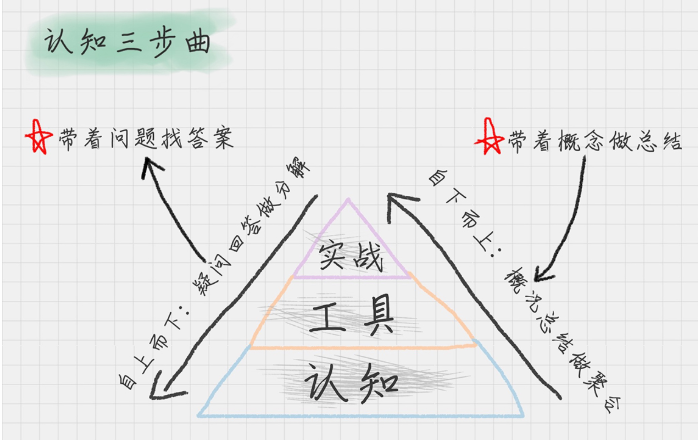
我本人也是很赞同这种说法,简单一句就是“知行合一”
总结
- 记录下你每天的认知
- 这些认知对应工具的哪些操作
- 做更多练习来巩固你的认知



